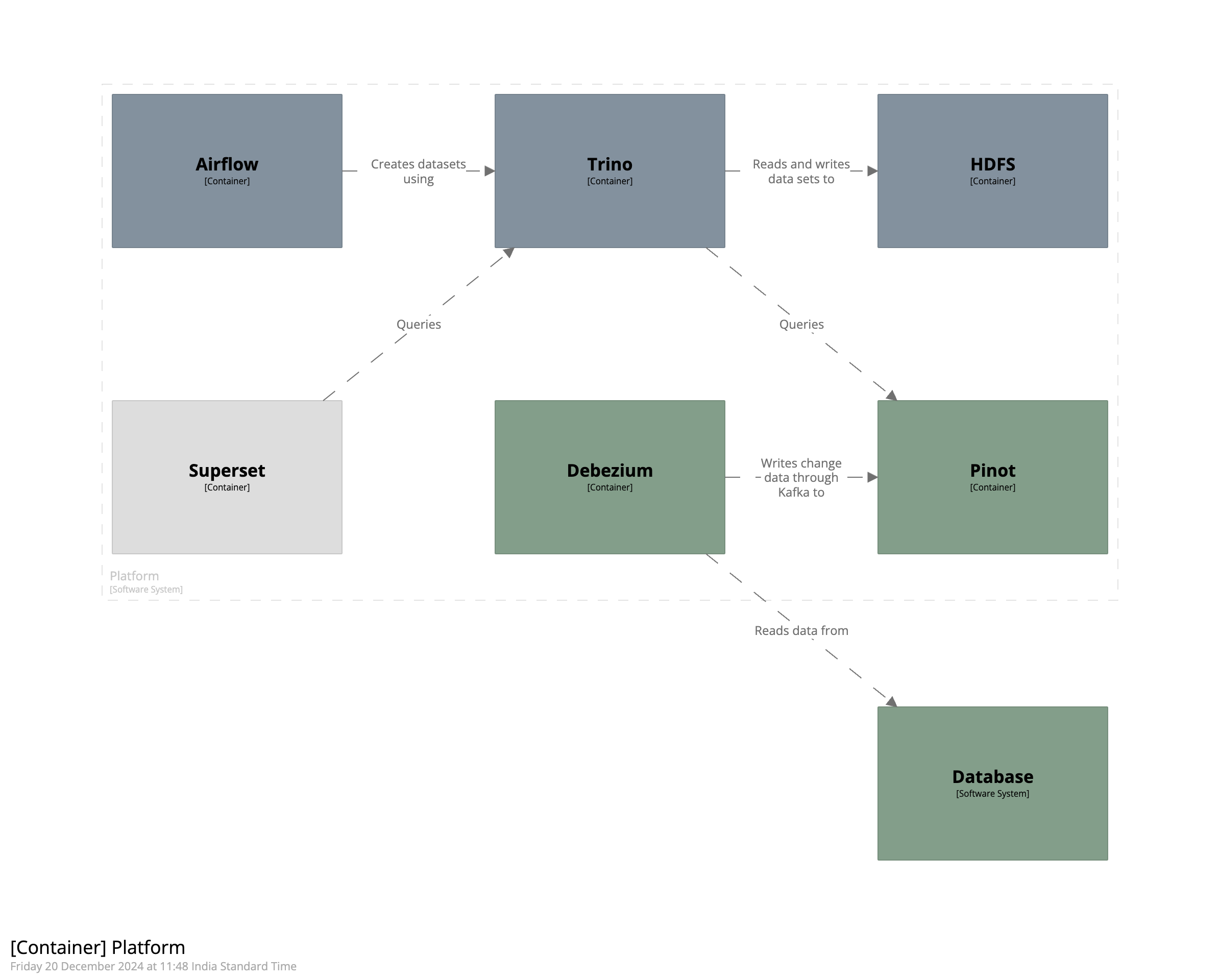
In the first part we saw the overall design of the system. In the second part we created a dataset that we can work with. In this post we’ll look at the first category of components and these are the ones that bring the data into the platform. We’ll see how we can stream data from the database using Debezium and store it in Pinot realtime tables.
Before we begin
The setup is still Dockerized and now has containers for Debezium, Kafka, and Pinot. In a nutshell, we’ll stream data from the Postgres instance into Kafka using Debezium and then write it to Pinot tables.
Getting started
In the first part of the series we briefly looked at Debezium. To recap, Debezium is a platform for change data capture. It consists of connectors which capture change data from the database and emit them as events into Kafka. Which database tables to monitor and which Kafka topic to write them to are specified as a part of the connector’s configuration. This configuration is written as a JSON object and sent to a specfic endpoint to spawn a new connector.
We’ll begin by creating configuration for a connector which will monitor all the tables in the database and route each of them to a dedicated Kafka topic.
1 | { |
There are two main parts to this configuration - name and config. The name is the name we’ve given to the connector. The config contains the actual configuration of the connector. We specify quite a few things in the config object. We specify the class of the connector which is the fully qualified name of the Java class, the credentials to connect to the database, whether or not to take a snapshot, how to route the data to the appropriate Kafka topics, and how to pass signals to Debezium.
While most of the configuration is self-explanatory, we’ll look closely at the ones related to snapshot, signalling, and routing. We set the snapshot mode to no_data which means that the connector will stream historical rows from the database. The only rows that will be emitted are the ones created or updated after the connector began running. We’ll use this setting in conjunction with signals to incrementally snapshot the tables we’re interested in. Signals are a way to modify the behavior of the connector, or to trigger a one-time action like taking an ad-hoc snapshot. When we combine no_data with signals, we can tell Debezium to selectively snapshot the tables we’re interested in. The signal.data.collection property specifies the name of the table which the connector will monitor for any signals that are sent to it.
Finally, we specify a route transform. We do this by writing a regex which matches against the fully qualified name of the table, and extracts only the table name. This allows us to send the data from every table into a dedicated Kafka topic of its own.
Notice how we’ve not specified which tables to monitor. Since it is a Postgres database, the connector will monitor all the tables in all the schemas within the database and stream them. Now that the configuration is created, we’ll POST it to the appropriate endpoint to create the connector.
1 | curl -H "Content-Type: application/json" -XPOST -d @tables/002-orders/debezium.json localhost:8083/connectors | jq . |
Now that the connector is created, we will signal it to initiate a snapshot. Signals are sent to the connector using rows inserted into the table. We’ll execute the following INSERT query to tell the connector to take a snapshot of the orders table.
1 | INSERT INTO debezium.signal |
The row tells the connector to initiate a snapshot, as indicated by execute-snapshot, and stream historical rows from the orders table in all the schemas within the database. It is an incremental snapshot so it will happen in batches. If we docker exec into the Kafka container and use the console consumer, we’ll find that all the rows eventually get streamed to the topic. The command to show it is given below.
1 | [kafka@kafka ~]$ kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic orders --from-beginning | wc -l |
We can compare this with the row count in the table using the following SQL command.
1 | SELECT COUNT(*) FROM public.orders; |
Now that the data is in Kafka, we’ll move on to how to stream it into a Pinot table. Before we get to that, we’ll look at what a table and schema are in Pinot.
A table in Pinot is similar to a table in a relational database. It has rows and columns where each column has a datatype. Tables are where data is stored in Pinot. Every table in Pinot has an associated schema and it is in the schema where the columns and their datatypes are defined. Tables can be realtime, where they store data from a streaming source such as Kafka. They can be offline, where they load data from batch sources. Or they can be hybrid, where they load data from both a batch source and a streaming source. Both the schema and table are defined as JSON.
Let’s start by creating the schema.
1 | { |
The schema defines a few things. It defines the name of the schema. This will also become the name of the table. Next, it defines the fields that will be present in the table. We’ve defined id, source, and created_at. The first two are specified in dimensionFieldSpecs and specify a column which becomes a dimension for any metric. The created_at field is specified in dateTimeFieldSpecs since it specifies a time column; Debezium will send timestamp columns as milliseconds since epoch. We’ve specified id as the primary key. Finally, enableColumnBasedNullHandling allows columns to have null values in them.
Once the schema is defined, we can create the table configuration.
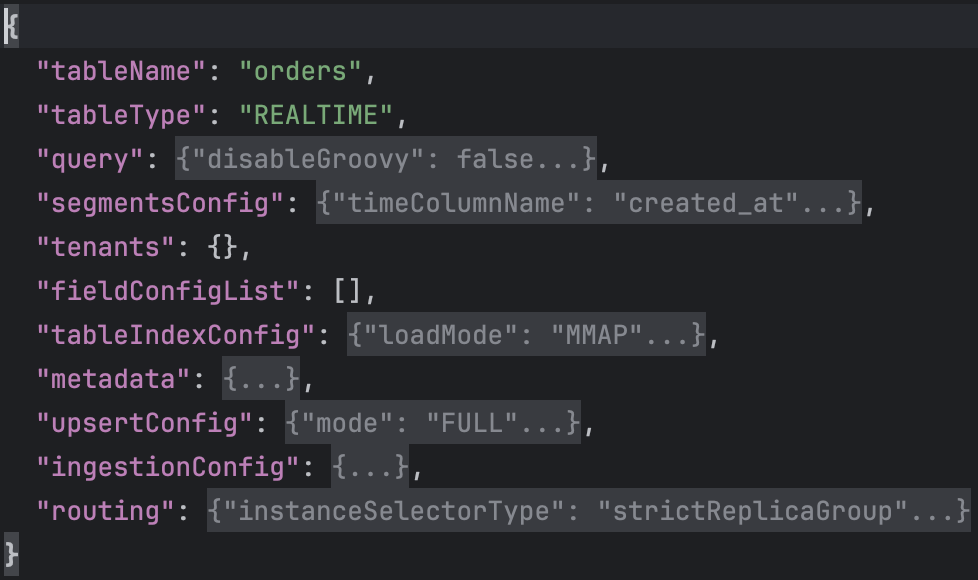
The configuration of tbe table is more involved than the schema so we’ll go over it one key at a time. We begin by specifying the tableName as “orders”. This matches the name of the schema. We specify tableType as “REALTIME” since the data we’re going to ingest comes from a Kafka topic. The query key specifies properties related to query execution. The segmentsConfig key specifies properties related to segments like the time column to use for creating a segment. The tenants key specifies the tenants for this table. A tenant is a logical namespace which restricts where the cluster processes queries on the table. The tableIndexConfig defines the indexing related information for the table. The metadata key specifies the metadata for this table. The upsertCconfig key specifies configuration for upserting into the table. The ingestionConfig key defines where we’d be ingesting data from and what field-level transformations we’d like to apply. The routing key defines properties that determine how the broker selects the servers to route.
The part of the configuration we’ll specifically look at is the ingestionConfig and upsertConfig. First, ingestionConfig.
1 | { |
In the ingestionConfig we specify the the Kafka topics to read from. In the snippet above, we’ve specified the “orders” topic. We also specify field-level transformations in transformConfigs. Here we extract the id, source, and created_at fields from the JSON payload generated by Debezium.
With the schema and table defined, we’ll POST them to the appropriate endpoints using curl. The following two commands create the schema followed by the table.
1 | curl -F schemaName=@tables/002-orders/orders_schema.json localhost:9000/schemas | jq . |
Once the table is created, it will begin ingesting data from the “orders” Kafka topic. We can view this data by opening the Pinot query console. Notice how the source column contains the entire “after” payload generated by Debezium.
That’s it. That’s how to stream data using Debezium into Pinot.