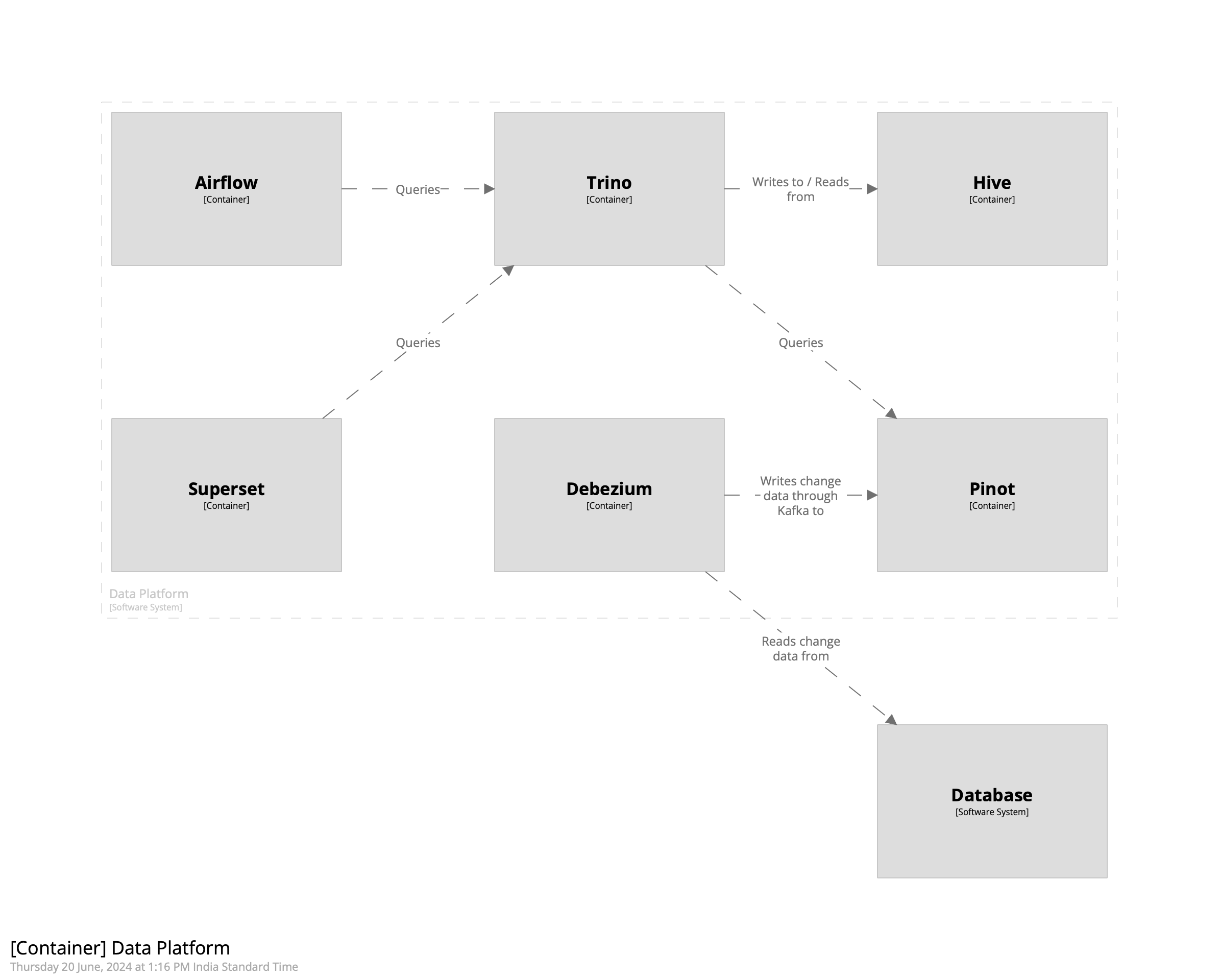
Problem Statement
Let’s start with the problem statement: create a todo list. The very first requirement that comes to mind when creating a todo list is the ability to add tasks to the list. For example, getting groceries. It’s also possible to add subtasks to the list. For example, getting apples and oranges are subtasks when getting groceries. The todo list may be shared with family and friends. They receive notifications when items are added or removed from the list, and have the ability to add or remove items. Only the one who created the list and the ones with whom the list has been shared may modify the list. The todo list may be displayed in the console or in the webpage. Finally, the todo list may be persisted in the database.
With these requirements in mind, we’ll begin by looking at the classes and methods that comprise our system, the design patterns we can apply, and finally go ahead and create the system. Please note that since the implementation is going to be in Python, it may seem like I’m trying to do Java in Python by creating too many classes. For example, Python has the concept of “factory function” rather than “factory method” since functions are first-class citizens of the language. You’ve been warned.
Design Patterns
Let’s begin with a quick refresher on design patterns. In a nutshell, design patterns allow us to write reusable, maintainable, and testable code by providing patterns for solving common software engineering problems. These patterns can be categorized into three types: behavioral, creational, and structural. Behavioral patterns describe how objects interact with each other. Creational patterns describe how objects can be created. Finally, structural patterns describe how objects can be composed to create larger systems.
In the context of the todo list, we’ll see the following patterns being used. We’ll take a quick look at these patterns and then map them onto the classes we’ll create.
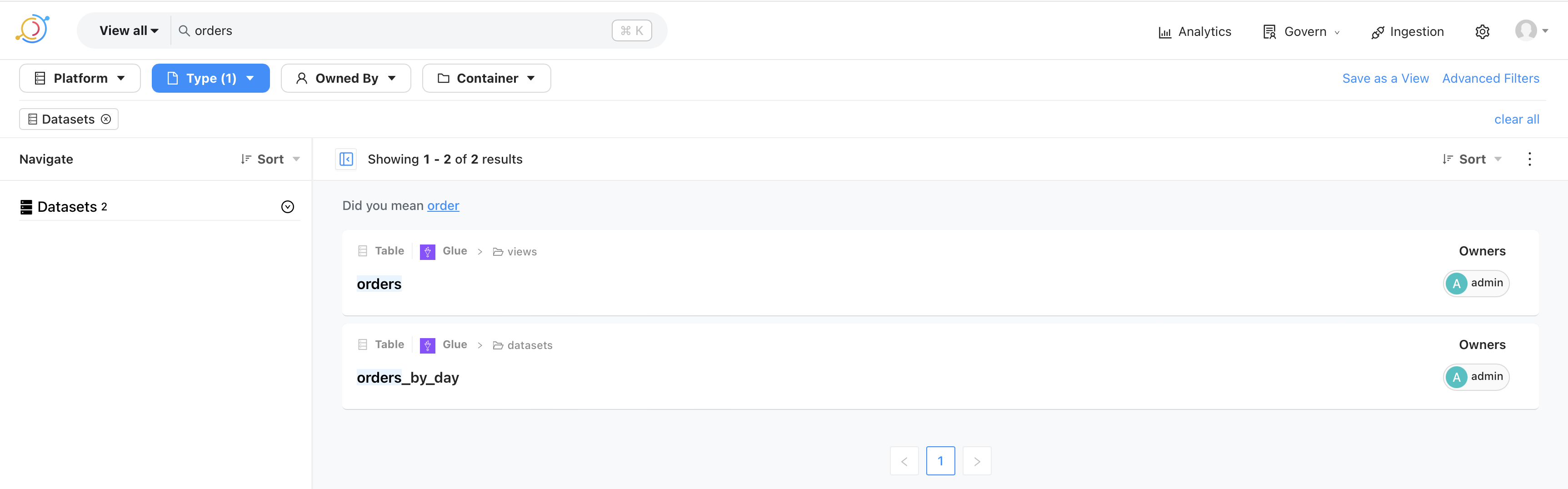
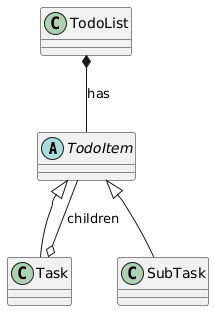
Composite Pattern
Composite pattern allows us to represent hierarchical, tree-like, data structures. The intention of this pattern is to ensure that composite objects (the non-leaf nodes), and individual objects (the leaf nodes) are treated the same. The UML diagram is given below.
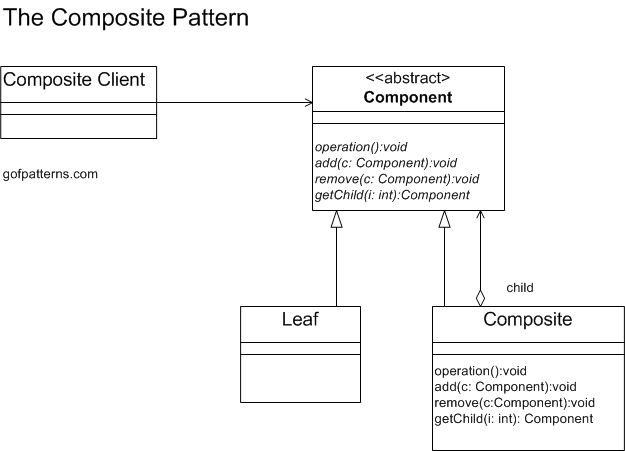
As we can see, the non-leaf Composite class is itself a Component and has a collection of Components. These may be Composites or Leafs. In our todo list example, we can model the the tasks and subtasks using this pattern. We begin by creating a top-level abstract class TodoItem which corresponds to top-level Component. The subtask can be represented by a SubTask class and is the Leaf. Finally, we’ll create a Task class which is the Composite.
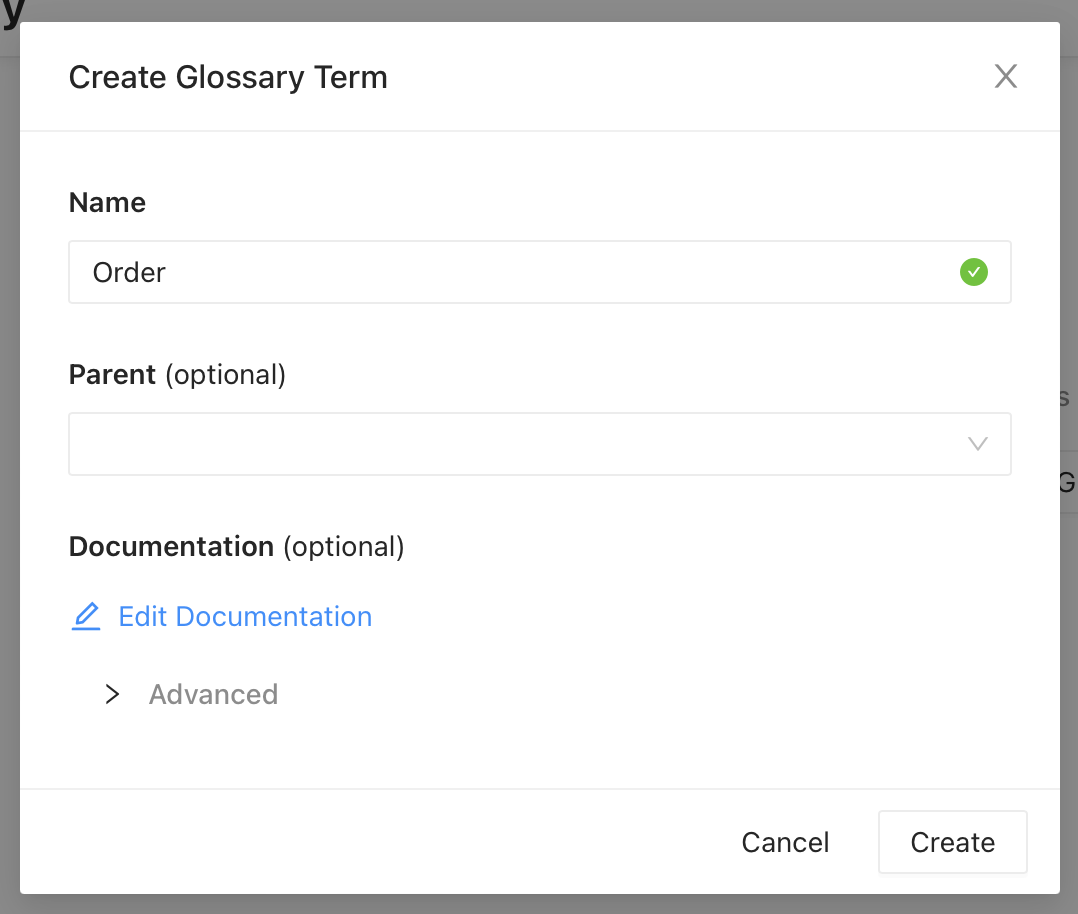
Adapter Pattern
The adapter pattern allows disparate components to work together seamlessly by reconciling differences between interfaces. It does so by providing a familiar interface that the client can talk to, and in turn using the interface of the underlying component. In other words, adapter pattern translates from one interface to another; the adapter calls specific methods on the adaptee when it is invoked. The UML diagram is given below.
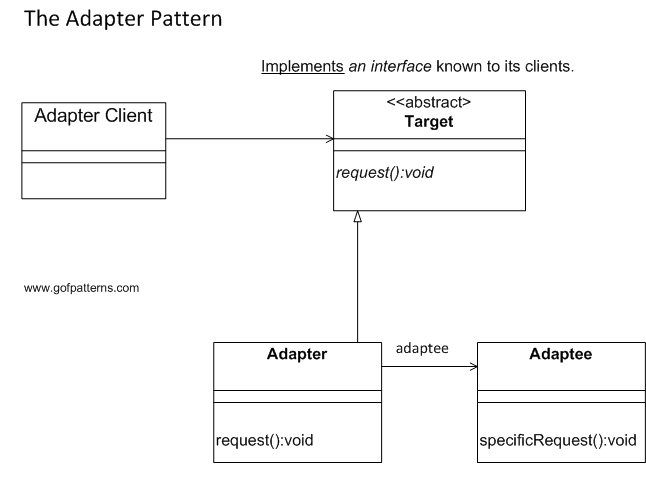
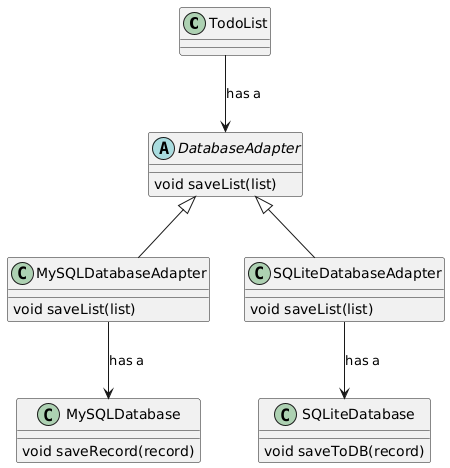
In our todo list example, we can model connection to database using a DatabaseAdapter. This allows us to expose a familiar set of methods to perform operations like saving the todo list to the database while abstracting the nitty-gritties of the actual database. This class can then be subclassed to provide functionality for specific databases. For example, a MySQLDatabaseAdapter for using MySQL as the database.
The advantage of using this approach is that it allows seamless migration between databases; we may start small with SQLiteDatabaseAdapter and then switch to MySQLDatabaseAdapter by simply changing which class we use. Since the interface exposed is the same, there will be minimal refactoring in the client code to make this transition.
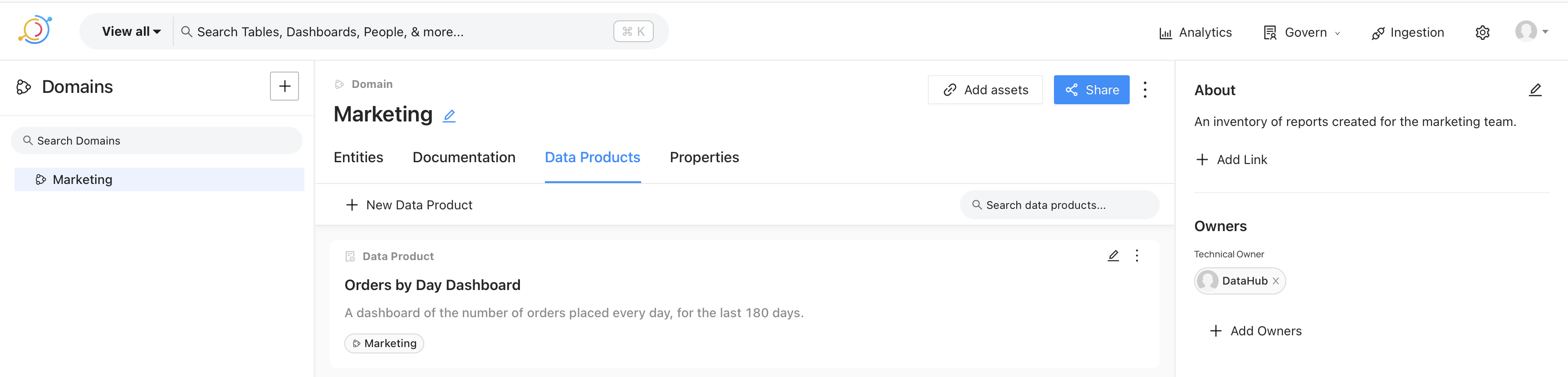
Strategy Pattern
The strategy pattern allows defining a family of algorithms, encapsulating each one, and making them interchangeable. This means we can define and pass algorithms around. There is a base class Strategy that defines the interface for the algorithm, and one or more concretions that provide the actual implementation. The UML diagram is given below.
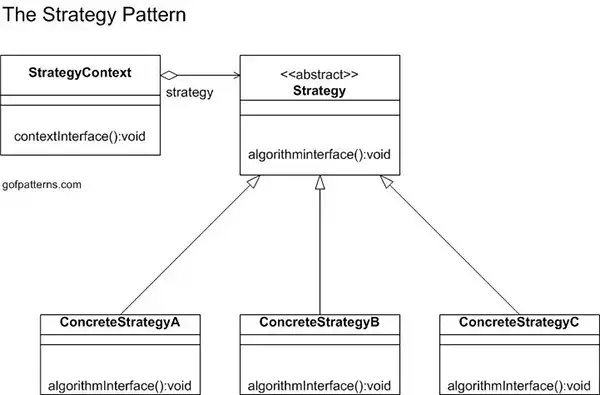
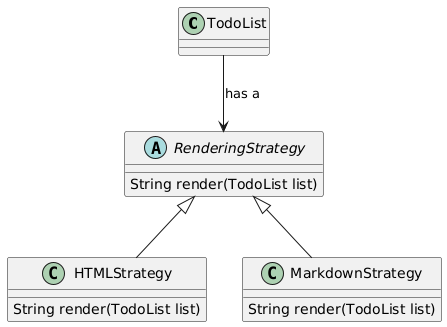
In our todo list example, we can design the rendering of the list as a strategy. For example, we can have a markdown strategy, an HTML strategy, etc. These different strategies produce different representations of the todo list.
Proxy Pattern
The proxy pattern encapsulates an object and allows itself to be used in place of the original object. Since the proxy is used in place of the original object, it enables use cases such as controlling access. There can be methods on the proxy which require authentication before the operation is performed on the original object.
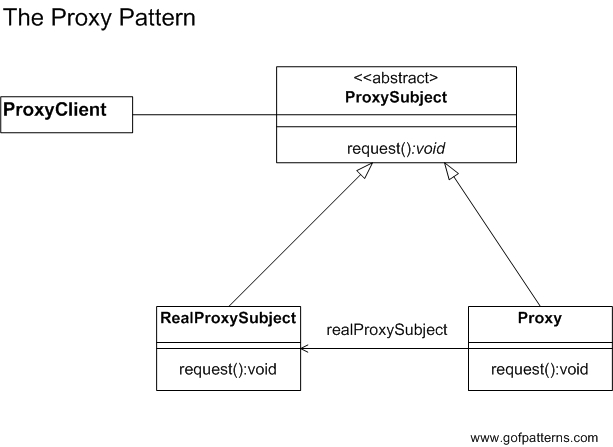
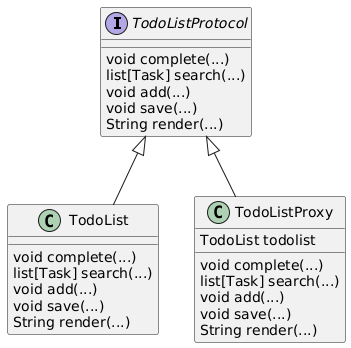
In our todolist example, we can create a proxy which ensures that only the owner of the list and those with whom it is shared can make changes to it. To do this, we’ll create an interface called TodoListProtocol which defines methods which the todo list must implement. This will be used by the TodoList class, which represents the actual todo list, and by the TodoListProxy which provides access control for the todo list. The proxy will require that that when a method call is made, the user making the call also be passed as an argument. Only if the user is the owner of the list or is one of the collaborators will the operation be performed.
Observer Pattern
The observer pattern allows objects, the observers, to be notified when the state of another object, the observable, changes.
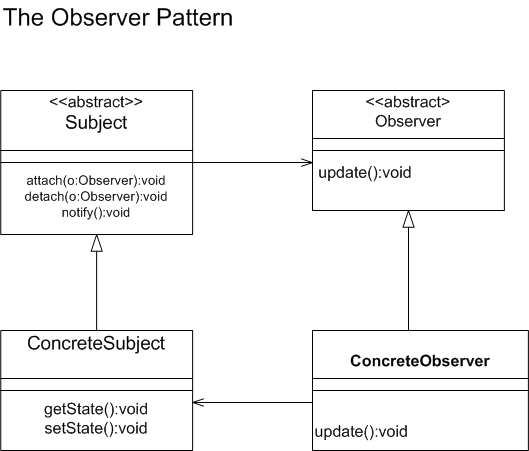
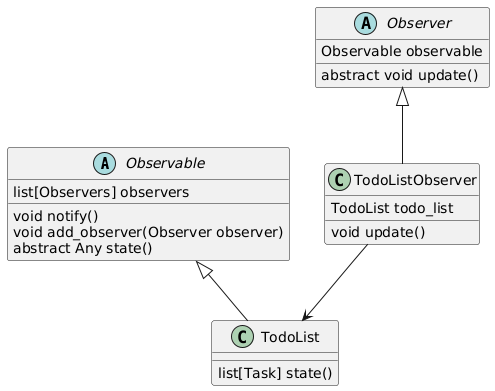
In our todolist example, we’ll create observers which get notified when the state of the todo list changes. We’ll create an abstract class called Observable which will be inherited by the TodoList class. This makes the class “observable”. We’ll create another class TodoListObserver which inherits the Observer class. This makes it the “observer” and it’ll be notified when changes happen to the todo list.
Now that we’ve looked at the design patterns we’ll use, let’s look at the code.
Code
User
We’ll begin with the simplest class first, the User class which represents a user of the system. The owners and collaborators of the list will be represented by this class.
1 |
|
Observer Pattern
Next, let’s add classes to create the observer pattern. We’ll begin by creating the abstract observable class. It’ll store the list of observers it has to notify, and require the subclasses to provide an implementation to return their state. Since the observers hold a reference to the observable they are observing, the method which returns the state will be used to find what’s changed.
The implementation for the Observable class is shown below.
1 |
|
Similarly, we’ll implement the Observer class. It requires its subclasses to provide an implementation for the update method which will be called by the Observable it’s observing.
1 |
|
Finally, we’ll create the concrete observer TodoListObserver. It notifies the user by sending them an email when the list is updated. For simplicity, however, we’ll just log a message to the console.
1 | class TodoListObserver(Observer): |
Composite Pattern
Next we’ll create the composite pattern. We’ll create a base class TodoItem which will be inherited by both the Task and SubTask class. It has basic fields that are required to define a task like an ID, a title, etc. and a couple of base methods to mark the item as complete or check if it’s complete.
1 |
|
The first of the subclasses is the Task class which we’ll implement next. A task is considered complete when it’s been marked completed and are all of its subtasks. Similarly, marking a task complete marks all the subtasks as complete.
1 |
|
To complete the composite, we’ll add the SubTask class.
1 |
|
If we look at the TodoItem, Task, SubTask classes, we can see the hierarchical structure where each Task, a non-leaf component, may have zero or more SubTasks, leaf components. Since both the Task and SubTask are instances of TodoItem, they have the same interface and can be used interchangeably.
Adapter Pattern
Next we’ll create a simple database adapter with a single method to save the todo list. There is only one method for the sake of simplicity but it’s easy to see how there can be more of these methods. We’ll start with a protocol called DatabaseAdapter. Think of a Python protocol to be similar to a Java interface.
1 | class DatabaseAdapter(Protocol): |
Next we’ll create two concrete classes which implement this protocol. The first class creates an adapter for MySQL and another for SQLite. Both of these classes take an instance of their specific database and use it to persist the todo list. Since each database instance may have its own set of methods to save data, an adapter provides a familiar interface that can be used elsewhere in the code.
1 | class MySQLAdapter(DatabaseAdapter): |
Strategy Pattern
Next, we’ll create strategies to render the todo list. We’ll start by creating a protocol called RenderingStratgy with a single method called render which returns a string representation of the todo list.
1 | class RenderingStrategy(Protocol): |
We’ll add a concrete strategy called TableRenderingStrategy which displays the tasks and subtasks in tabular format.
1 | class TableRenderingStrategy(RenderingStrategy): |
Proxy Pattern
To create the proxy pattern, we’ll create the protocol, TodoListProtocol, for both the todo list and the proxy. Let’s start with the protocol which defines the methods that are common to both the todo list and the proxy. As we can see, there’s methods to mark the list as complete, to search for tasks, to render the list, and so on.
1 | class TodoListProtocol(Protocol): |
Next we’ll add the implementation for the TodoList which implemenets this protocol.
1 |
|
Notice how it implements both TodoListProtocol and Observable. In the add method, we call notify which updates all the observers for this list.
Finally, we’ll add the proxy for TodoList. The proxy authenticates each call to the underlying TodoList by checking whether the user trying to access the list is the owner or a collaborator.
1 |
|
Running the Code
Let’s wire the pieces together and run them. We’ll create an adapter, a rendering strategy, and an observer. Since we’ll use dependency injection, we’ll pass these obhects to the appropriate methods.
1 | adapter: DatabaseAdapter = MySQLAdapter(db={}) |
Next, let’s create the todo list itself.
1 | todolist = TodoList( |
Notice we’ve added tasks and subtasks to the list. We’ve also added a collaborator and an observer to the list. We’ll finish adding the observer by updating its observable property. This will allow it to fetch the state from the list when it gets updated.
1 | observer.observable = todolist |
Next, we’ll create a proxy for the list so that we can authenticate the calls.
1 | proxy = TodoListProxy(todolist=todolist) |
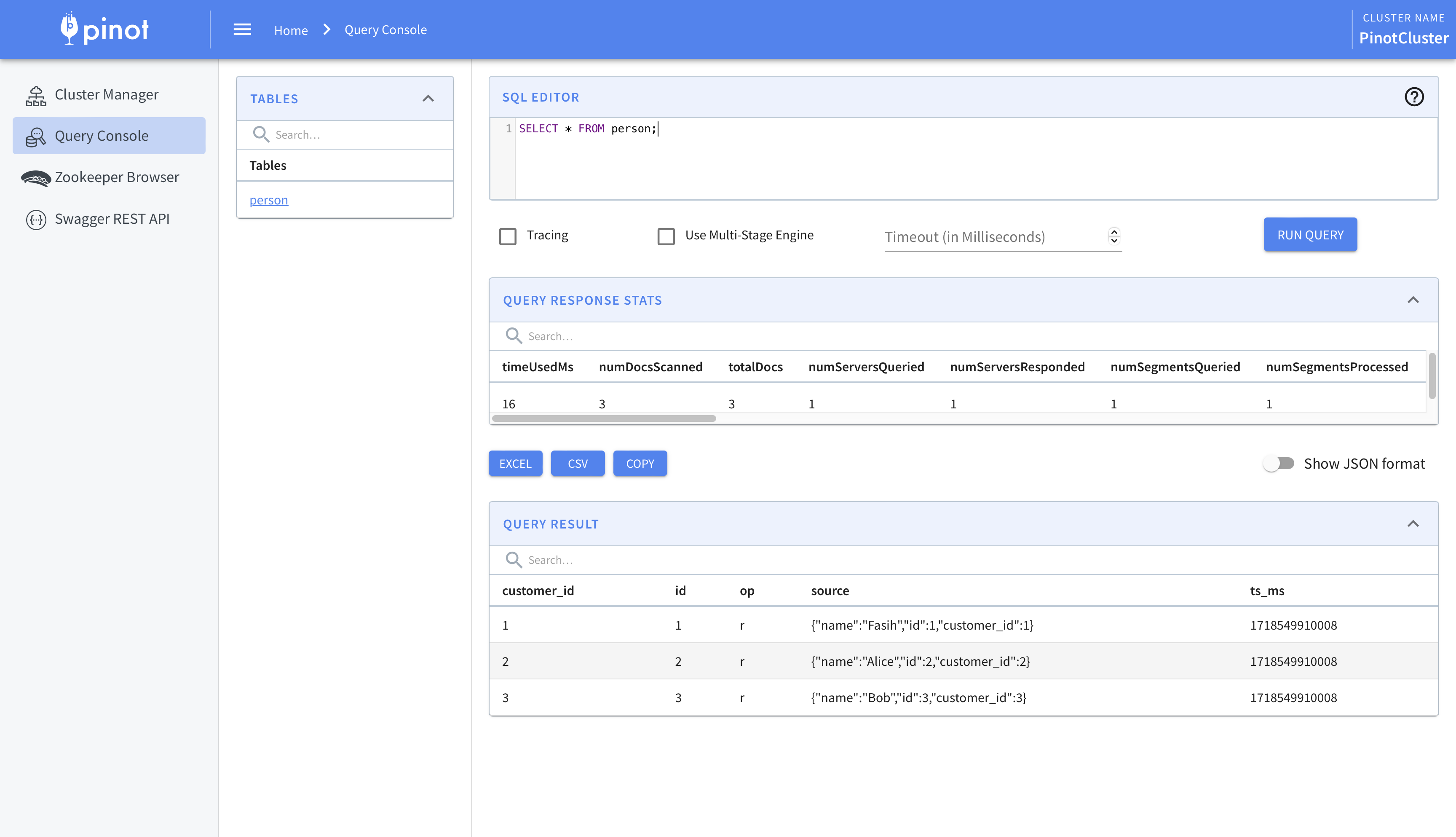
We can now make method calls to see the code in action. Let’s begin by adding a task.
1 | proxy.add( |
This produces the following output in the console. Since John Doe added an item to the list, Jane Doe will be notified of the change.
1 | Notify jane.doe@gmail.com about changed state |
Next, we’ll render the list.
1 | print( |
The list is rendered as follows. The subtasks are marked with an arrow to indicate a level of nesting.
1 | Title Status |
Finally, we’ll make an unauthenticated call to see proxy in action.
1 | proxy.add( |
This raises an exception saying that the user is not authenticated.
That’s it. That’s how to create a todo list.
]]>