Property-based testing with Hypothesis
I’d previously written about property-based testing in Clojure. In this blog post I’d like to talk about how we can do the same in Python using the Hypothesis library. We’ll begin with a quick recap of what property-based testing is, and then dive head-first into writing some tests.
What is property-based testing?
Before we get into property-based testing, let’s talk about how we usually write tests. We provide a known input to the code under test, capture the resulting output, and write an assertion to check that it matches our expectations. This technique of writing tests is called example-based testing since we provide examples of inputs that the code has to work with.
While this technique works, there are some drawbacks to it. Example-based tests take longer to write since we need to come up with examples ourselves. Also, it’s possible to miss out on corner cases.
In contrast, property-based testing allows us to specify the properties of the code and test that they hold true under a wide range of inputs. For example, if we have a function f that takes an integer and performs some computation on it, a property-based test would test it for positive integers, negative integers, very large integers, and so on. These inputs are generated for us by the testing framework and we simply need to specify what kind of inputs we’re looking for.
Having briefly discussed what property-based testing is, let’s write some code.
Writing property-based tests
Testing a pure function
Let’s start with a function which computes the n’th Fibonacci number.
1 |
|
The sequence of numbers goes 0, 1, 1, 2, 3, etc. We can see that all of these numbers are greater than or equal to zero. Let’s write a property-based test to formalize this.
1 | from hypothesis import given, strategies as st |
In the code snippet above, we’ve wrapped our test using the @given decorator. This makes it a property-based test. The argument to the decorator is a search strategy. A search strategy generates random data of a given type for us. Here we’ve specified that we need integers. We can now run the test using pytest as follows.
1 | PYTHONPATH=. pytest . |
The test fails with the following summary.
1 | FAILED test/functions/test_fibonacci.py::test_fibonacci - ExceptionGroup: Hypothesis found 2 distinct failures. (2 sub-exceptions) |
When looking at the logs, we find that the first failure is because the maximum recursion depth is reached when the value of n is large.
1 | n = 453 |
The second failure is because the function returned a negative integer when the value of n is negative; in this case it is n=-1. This violates our assertion that the numbers in the Fibonacci sequence are non-negative.
1 | +---------------- 2 ---------------- |
To remedy the two failures above, we’ll add an assertion at the top of the function which will ensure that the input n is in some specified range. The updated function is given below.
1 |
|
We’ll update our test cases to reflect this change in code. The first test case checks the function when n is between 0 and 300.
1 |
|
The second case checks when n is large. In this case we check that the function raises an AssertionError.
1 |
|
Finally, we’ll check the function with negative values of n. Similar to the previous test case, we’ll check that the function raises an AssertionError.
1 |
|
Testing persistent data
We’ll now use Hypothesis to generate data that we’d like to persist in the database. The snippet below shows a Person model with fields to store name and date of birth. The age property returns the current age of the person in years, and the MAX_AGE variable indicates that the maximum age we’d like to allow in the system is 120 years.
1 | class Person(peewee.Model): |
We’ll add a helper function to create Person instances as follows.
1 | def create(name: str, dob: datetime.date) -> Person: |
Like we did for the function which computes Fibonacci numbers, we’ll add a test case to formalize this expectation. This time we’re generating random names and dates of birth and passing them to the helper function.
1 |
|
I’m persisting this data in a Postgres table and the create_tables fixture ensures that the tables are created before the test runs.
Upon running the test we find that it fails for two cases. The first case is when the input string contains a NULL character \x00. Postgres tables do not allow strings will NULL characters in them.
1 | ValueError: A string literal cannot contain NUL (0x00) characters. |
The second case is when the date of birth is in the future.
1 | AssertionError: assert 0 <= -1 |
To remedy the first failure, we’ll have to sanitize the name input string that gets stored in the table. We’ll create a helper function which removes any NULL characters from the string. This will be called before name gets saved in the table.
1 | def sanitize(s: str) -> str: |
To remedy the second failure, we’ll add an assertion ensuring that the age is less than or equal to 120. The updated create function is shown below.
1 | def create(name: str, dob: datetime.date) -> Person: |
We’ll update the test cases to reflect these changes. Let’s start by creating two variables that will hold the minimum and maximum dates allowed.
1 | MIN_DATE = datetime.date.today() - datetime.timedelta(days=Person.MAX_AGE * 365) |
Next, we’ll add a test to ensure that we raise an AssertionError when the string contains only NULL characters.
1 |
|
Next, we’ll add a test to ensure that dates cannot be in the future.
1 |
|
Similarly, we’ll add a test to ensure that dates cannot be more than 120 years in the past.
1 |
|
Finally, we’ll add a test to ensure that in all other cases, the function creates a Person instance as expected.
1 |
|
The tests pass when we rerun them so we can be sure that the function behaves as expected.
Testing a REST API.
Finally, we’ll look at testing a REST API. We’ll create a small Flask app with an endpoint which allows us to create Person instances. The API endpoint is a simple wrapper around the create helper function and returns the created Person instance as a dictionary.
1 |
|
We’ll add a test to generate random JSON dictionaries which we’ll pass as the body of the POST request. The test is given below.
1 |
|
Similar to the tests for create function, we test that the API returns a response successfully when the inputs are proper.
That’s it. That’s how we can leverage Hypothesis to test Python code. You’ll find the code for this post in the Github repository.
Programming Puzzles 4
In the previous post we looked at computing the Fibonacci series both with and without dynamic programming. In this post we’ll look at another example where dynamic programming is applicable. The example is borrowed from ‘Introduction to Algorithms’ by CLRS and implemented in Python. By the end of this post we’ll try to develop an intuition for when dynamic programming applies.
Rod Cutting
The problem we are presented with is the following: given a steel rod, we’d like to find the optimal way to cut it into smaller rods. More formally, we’re presented with a rod of size n inches and a table of prices pi. We’d like to determine the maximum revenue rn that we can obtain by cutting the rod and selling it. If the price pn of the rod of length n is large enough, we may sell the rod without making any cuts.
The table of prices that we’ll work with is given below.
| length i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| price pi | 1 | 5 | 8 | 9 | 10 | 17 | 17 | 20 | 24 | 30 |
Consider a rod of length 4 inches. The maxium revenue we can obtain is 10 by cutting the rod into two parts of length 2 inches each.
Given a rod of n inches, we may sell it uncut or we may sell it by cutting it into smaller pieces. Since we do not know the size of the cuts to make, we will have to consider all possible sizes. Once we make a cut of size
It states that the revenue rn is the maximum revenue obtained by considering all cuts of size
1 | def rod_cut(p: list[int], n: int) -> int: |
We can verify the results by calling the function for a rod of size 4 and passing the table of prices.
1 | p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] |
The recursive version, however, does redundant work. Consider the rod of size n = 4. We will have to consider cuts of size
We can use dynamic programming to solve this problem by modifying the rod_cut function as follows.
1 | def rod_cut(p: list[int], t: list[int | None], n: int) -> int: |
Notice how we’ve introduced a table t which stores the maximum revenue obtained by cutting a rod of size n. This allows us to reuse previous computations. We can run this function and verify the result.
1 | t = [None] * 11 |
The question that we’re left with is the following: how did we decide that the problem could be solved with dynamic programming? There are two key factors that help us in deciding if dynamic programming can be used. The first is overlapping subproblems and the second is optimal substructure.
For a dynamic programming algorithm to work, the number of subproblems must be small. This means that the recursive algorithm which solves the problem encounters the same subproblems over and over again. When this happens, we say that the problem we’re trying to solve has overlapping subproblems. In the rod cutting problem, when we try to cut a rod of size 4, we consider cuts of size
The second factor is optimal substructure. When a problem exhibits optimal substructure, it means that the solution to the problem contains within it the optimal solutions to the subproblems; we build an optimal solution to the problem from optimal solutions to the subproblems. The rod-cutting problem exhibits optimal substructure because the optimal solution to cutting a rod of length
Moving on. So far our algorithm has returned the optimal value of the solution. In other words, it returned the maximum revenue that can be obtained by optimaly cutting the rod. We often need to store the choice that led to the optimal solution. In the context of the rod cutting problem, this would be the lengths of the cuts made. We can do this by keeping additional information in a separate table. The following code listing is a modification of the above function with an additional table s to store the value of the optimal cut.
1 | def rod_cut(p: list[int], s: list[int | None], t: list[int | None], n: int) -> int: |
In this version of the code, we store the size of the cut being made for a rod of length n in the table s. Once we have this information, we can reconstruct the optimal solution. The function that follows shows how to do that.
1 | def optimal_cuts(s: list[int | None], n: int) -> list[int]: |
Finally, we call the function to see the optimal solution. Since we know that the optimal solution for a rod of size 4 is to cut it into two equal halves, we’ll use
1 | n = 4 |
That’s it. That’s how we can use dynamic programming to optimally cut a rod of size
Programming Puzzles 3
In this post, and hopefully in the next few posts, I’d like to devle into the topic of dynamic programming. The aim is to develop an intuition for when it is applicable by solving a few puzzles. I’ll be referring to the chapter on dynamic programming in ‘Introduction to Algorithms’ by CLRS, and elucidating it in my own words.
Dynamic Programming
The chapter opens with the definition of dynamic programming: it is a technique for solving problems by combining solutions to subproblems. The subproblems may have subsubproblems that are common between them. A dynamic programming algorithm solves these subsubproblems only once and saves the result, thereby avoiding unnecessary work. The term “programming” refers to a tabular method in which the results of subsubproblems are saved in a table and reused when the same subsubproblem is encountered again.
All of this is abstract so let’s look at a concrete example of computing the Fibonacci series.
1 | def fibonacci(n: int) -> int: |
The call graph for fibonacci(4) is given below.

As we can see, we’re computing fibonacci(2) twice. In other words, the subsubproblem of computing fibonacci(2) is shared between fibonacci(4) and fibonacci(3). A dynamic programming algorithm would solve this subsubproblem only once and save the result in a table and reuse it. Let’s see what that looks like.
1 | def fibonacci(n: int) -> int: |
In the code above, we create a table T which stores the Fibonacci numbers. If an entry exists in the table, we return it immediately. Otherwise, we compute and store it. This recursive approach, with results of subsubproblems stored in a table, is called “top-down with memoziation”; the table is called the “memo”. We begin with the original problem and then proceed to solve it by finding solutions to smaller subproblems. The procedure which computes the solution is said to be “memoized” as it remembers the previous computations.
Another approach is called “bottom-up” in which the solutions to the smaller subproblems are computed first. This depends on the notion that subproblems have “size”. In this approach, a solution to the subproblem is found only when the solutions to its smaller subsubproblems have been found. We can apply this approach when computing the Fibonacci series.
1 | def fibonacci(n: int) -> int: |
As we can see, the larger numbers in the Fibonacci series are computed only when the smaller numbers have been computed.
This was a small example of how dynamic programming algorithms work. They are applied to problems where subproblems share subsubproblems. The solutions to these subsubproblems are stored in a table and reused when they are encountered again. This enables the algorithm to work more efficiently as it avoids the rework of solving the subsubproblems.
In the next post we’ll look at another example of dynamic programming that’s presented in the book and implement it in Python to further our understanding of the subject.
Detecting disguised email addresses in a corpus of text
I’d recently written about an experimental library to detect PII. When discussing it with an acquaintance of mine, I was told that PII can also be disguised. For example, a corpus of text like a review or a comment can contain email address in the form “johndoeatgmaildotcom”. This led me to update the library so that emails like these can also be flagged. In a nutshell, I had to update the regex which was used to find the email.
Example
This is best explained with a few examples. In all of the examples, we begin with a proper email and disguise it one step at a time.
1 | column = Column(name="comment") |
All of these assertions pass and the regex detector is able to flag all of these examples as email.
An experiemental library to detect PII
I recently created an experimental library, detectpii, to detect PII data in relational databases. In this post we’ll take a look at the rationale behind the library and it’s architecture.
Rationale
A common requirement in many software systems is to store PII information. For example, a food ordering system may store the user’s name, address, phone number, and email. This information may also be replicated into the data warehouse. As a matter of good data governance, you may want to restrict access to such information. Many data warehouses allow applying a masking policy that makes it easier to redact such values. However, you’d have to specify which columns to apply this policy to. detectpii makes it easier to identify such tables and columns.
My journey into creating this library began by looking for open-source projects that would help identify such information. After some research, I did find a few projects that do this. The first project is piicatcher. It allows comparing the column names of tables against regular expressions that represent common PII column names like user_name. The second project is CommonRegex which allows comparing column values against regular expression patterns like emails, IP addresses, etc.
detectpii combines these two libraries to allow finding column names and values that may potentially contain PII. Out of the box, the library allows scanning column names and a subset of its values for potentially PII information.
Architecure
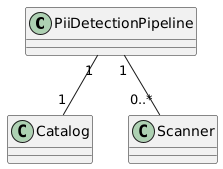
At the heart of the library is the PiiDetectionPipeline. A pipeline consists of a Catalog, which represents the database we’d like to scan, and a number of Scanners, which perform the actual scan. The library ships with two scanners - the MetadataScanner and the DataScanner. The first compares column names of the tables in the catalog against known patterns for the ones which store PII information. The second compares the value of each column of the table by retrieving a subset of the rows and comparing them against patterns for PII. The result of the scan is a list of column names that may potentially be PII.
The design of the library is extensible and more scanners can be added. For example, a scanner to use a proprietary machine learning algorithm instead of regular expression match.
Usage
To perform a scan, we create a pipeline and pass it a catalog and a list of scanners. To inititate the scan, we call the scan method on the pipeline to get back a list of PII columns.
1 | from detectpii.catalog import PostgresCatalog |
That’s it. That’s how to use the library to detect PII columns in tables.
A question on algebraic manipulations
In the exercises that follow the chapter on algebraic manipulations, there is a question that pertains to expressing an integer
Question
If
Solution
From the question,
What do we deduce from this? We find that both the expressions contributed an
This leaves us with two pairs of numbers —
What integers would we need for
Setting up a data catalog with DataHub
In a previous post we’d seen how to create a realtime data platform with Pinot, Trino, Airflow, and Debezium. In this post we’ll see how to setup a data catalog using DataHub. A data catalog, as the name suggests, is an inventory of the data within the organization. Data catalogs make it easy to find the data within the organisation like tables, data sets, reports, etc.
Before we begin
My setup consists of Docker containers required to run DataHub. While DataHub provides features like data lineage, column assertions, and much more, we will look at three of the simpler featuers. One, we’ll look at creating a glossary of the terms that will be used frequently in the organization. Two, we’ll catalog the datasets and views that we saw in the previous post. Three, we’ll create an inventory of dashboards and reports created for various departments within the organisation.
The rationale for this as follows. Imagine a day in the life of a business analyst. Their responsibilities include creating reports and dashboards for various departments. For example, the marketing team may want to see an “orders by day” dashboard so that they can correlate the effects of advertising campaigns with an uptick in the volume of orders. Similarly, the product team may want a report of which features are being used by the users. The requests of both of these teams will be served by the business analyts using the data that’s been brought into the data platform. While they create these reports and dashboards, it’s common for them to receive queries asking where a team member can find a certain report or how to interpret a data point within a report. They may also have to search for tables and data sets to create new reports, acquaint themselves with the vocabulary of the various departments, and so on.
A data catalog makes all of this a more efficient process. In the following sections we’ll see how we can use DataHub to do it. For example, we’ll create the definition of the term “order”, create a list of reports created for the marketing department, and bring in the views and data sets so that they become searchable.
The work of data scientists is similar, too, because they create data sets that can be reused across various models. For example, data sets representing features for various customers can be stored in the platform, made searchable, and used with various models. They, too, benefit from having a data catalog.
Finally, it helps bring people up to speed with the data that is consumed by their department or team. For example, when someone joins the marketing team, pointing them to the data catalog helps them get productive quickly by finding the relevant reports, terminology, etc.
Ingesting data sets and views
To ingest the tables and views, we’ll create a data pipeline which ingets metadata from AWS Glue and writes it to the metadata service. This is done by creating a YAML configuration in DataHub that specifies where to ingest the metadata from, and where to write it. Once this is created, we can schedule it to run periodically so that it stays updated with Glue.
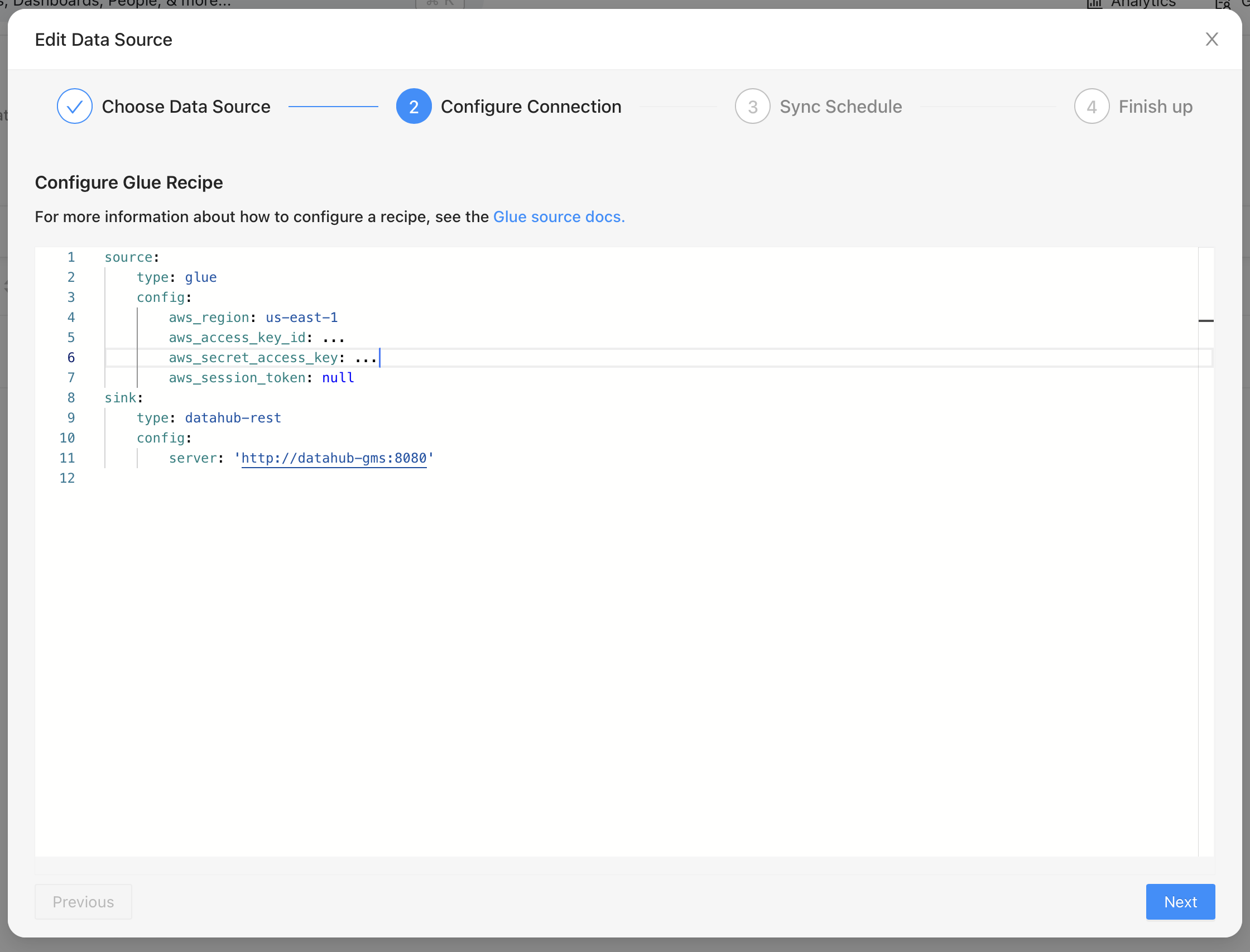
The image above shows how we define a “source” and how we ingest it into a “sink”. Here we’ve specified that we’d like to read from Glue and write it to DataHub’s metadata service.
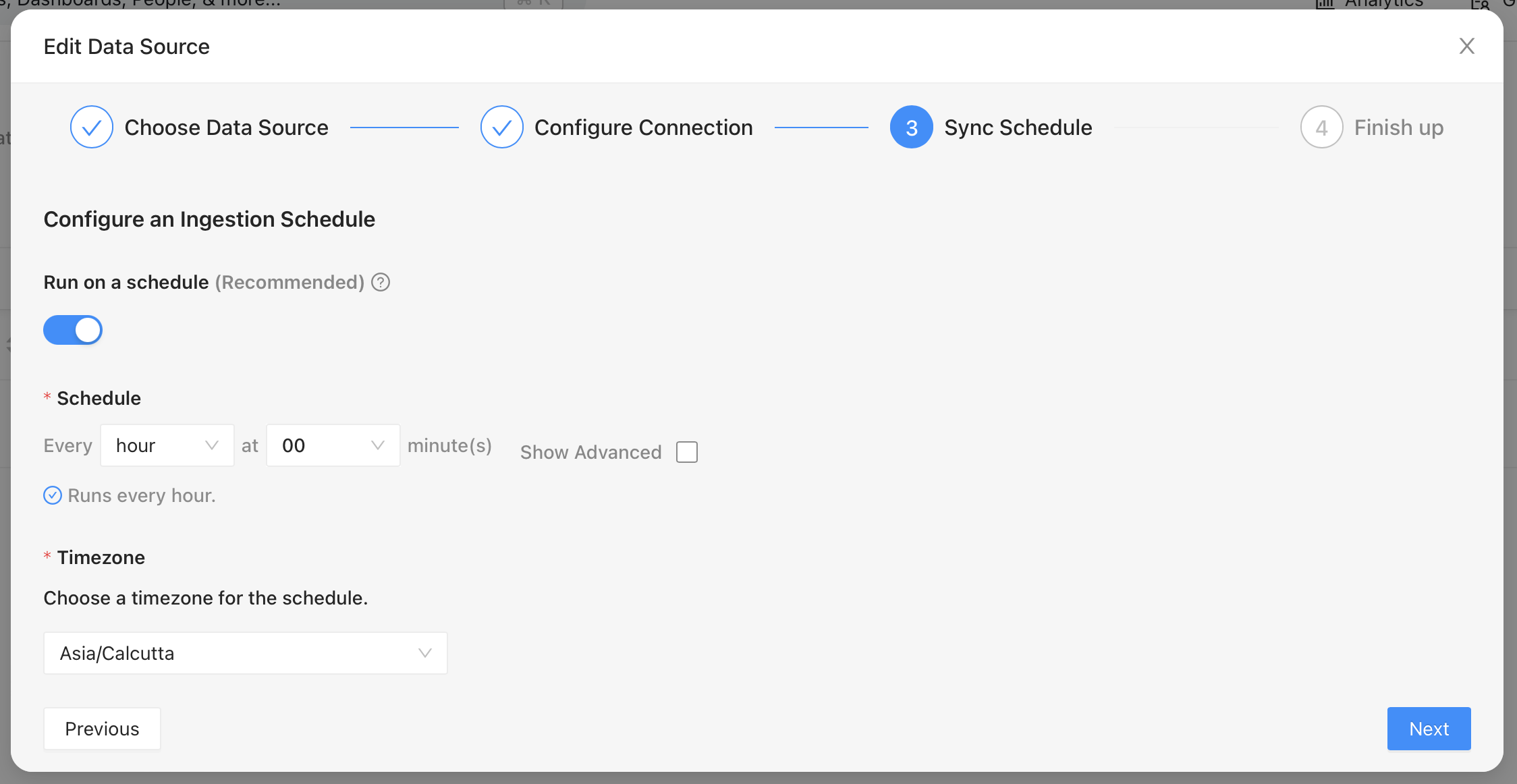
Once the source and destination are defined, we can set a schedule to run the ingestion. This will bring in the metadata about the data sets and views we’ve created in Glue.
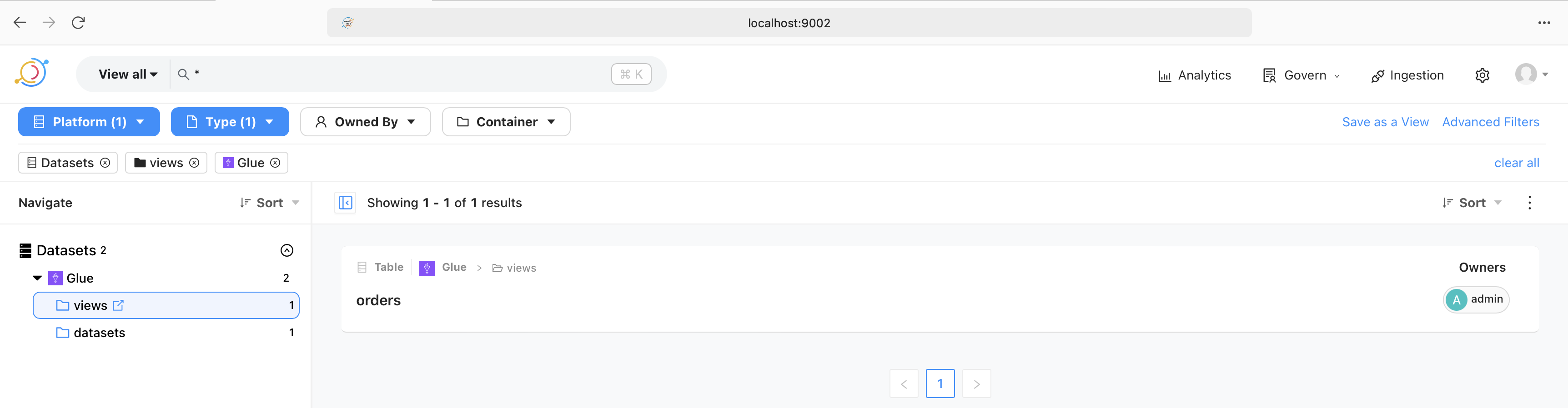
The image above shows that a successful run of the ingestion pipeline brings in the views and data sets. These are then browsable in the UI. Similarly, they are also searchable as shown in the following image.
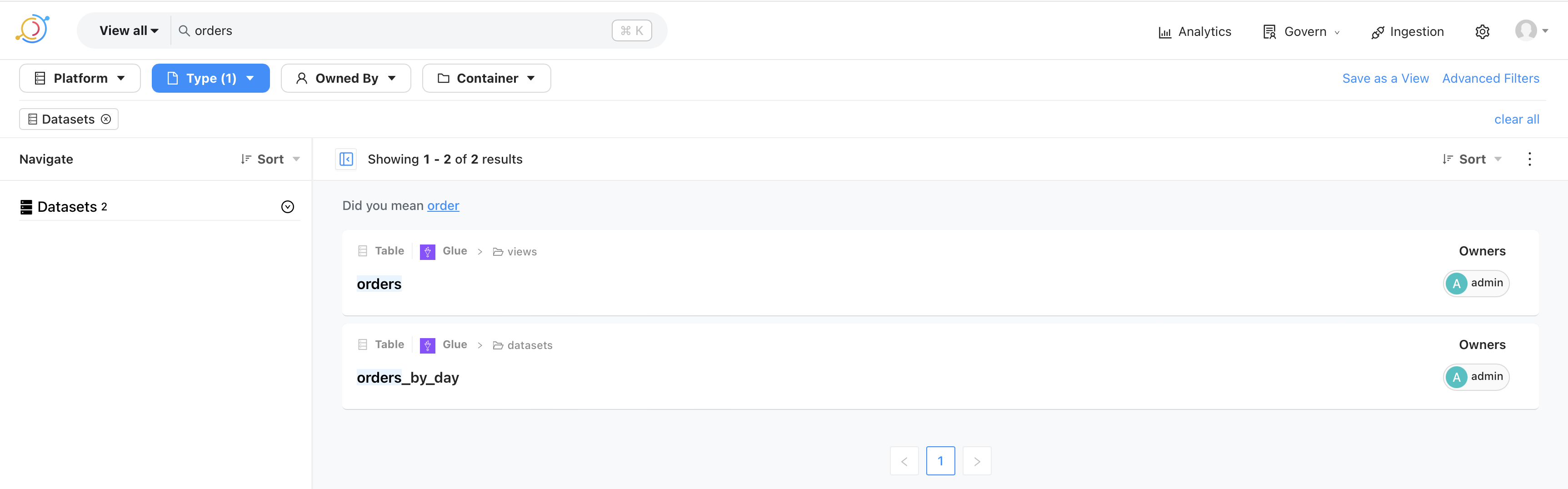
This makes it possible for the analysts and the data scientists to quickly locate data sets.
Defining the vocabulary
Next, we’ll create the definition of the word “order”. This can be done from the UI as shown below. The definition can be added by editing the documentation.
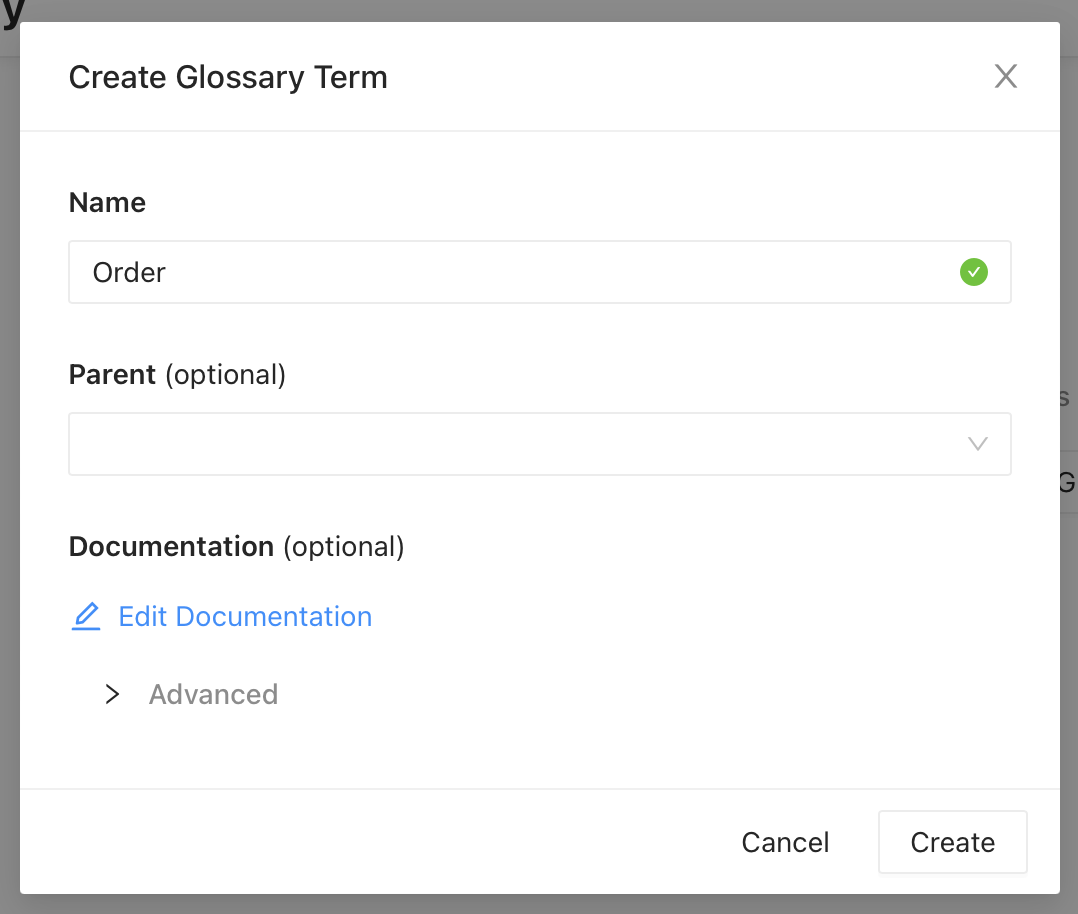
Once created, this is available under “Glossary” and in search results.

Data products
Finally, we’ll create a data product. This is the catalog of reports and dashboards created for various departments. For example, the image below shows a dashboard created for the marketing team.
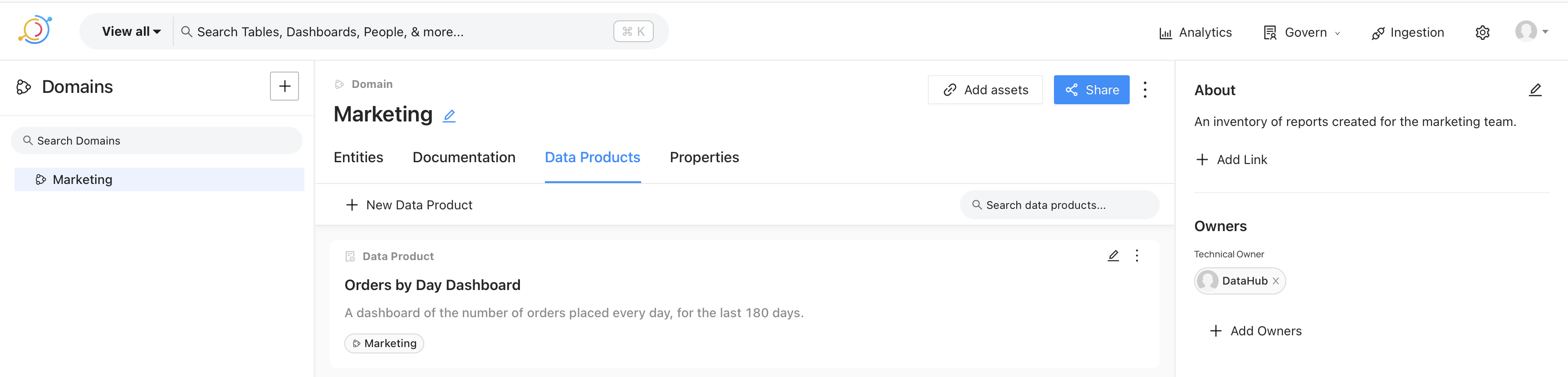
Expanding the dashboard allows us to look at the documentation for the report. This could contain the definition of the terms used in the report, as shown on the bottom right, a link to the dashboard in Superset, definitions of data points, report owners, and so on.
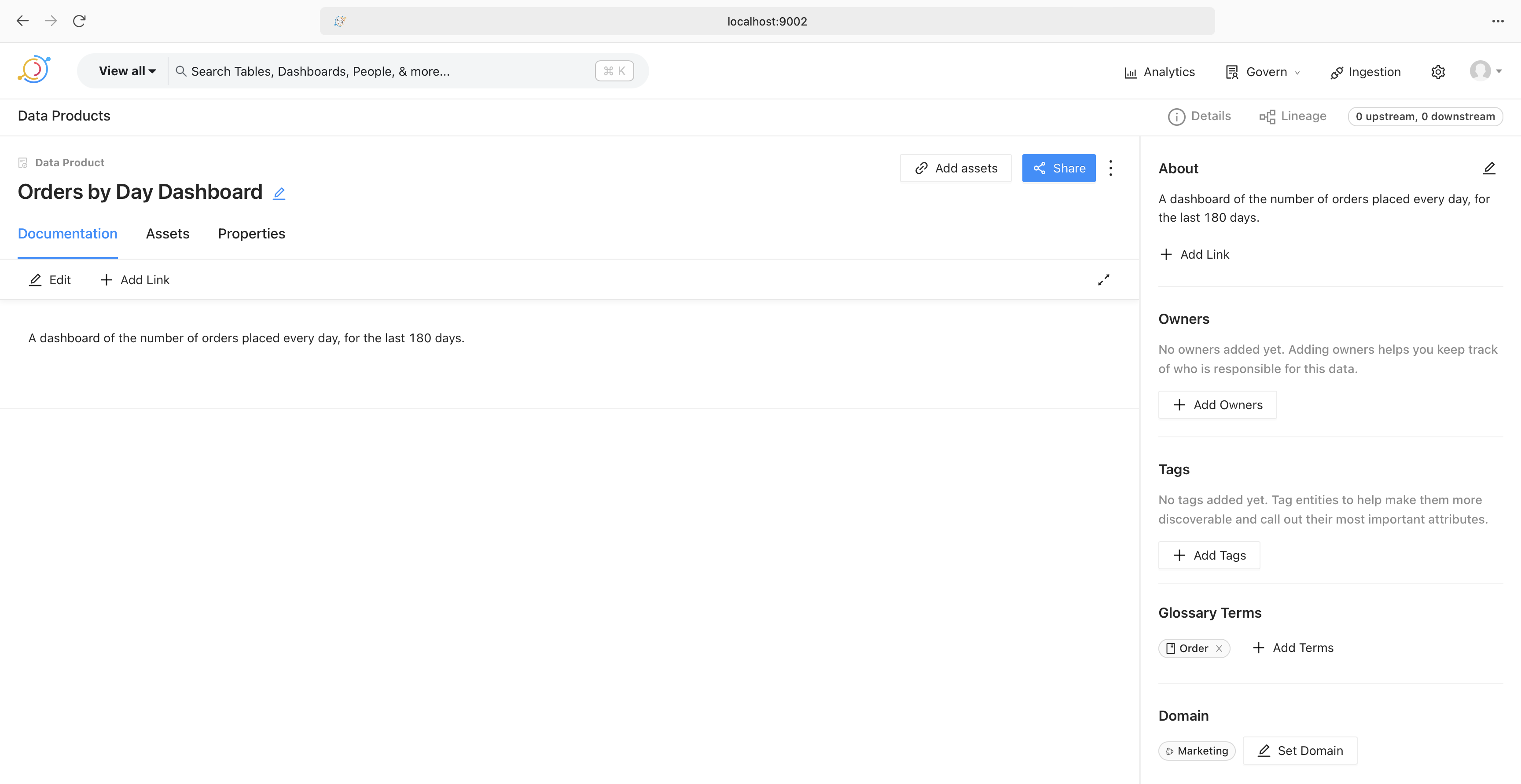
That’s it. That’s how a data catalog helps streamline working with data.
Programming Puzzles 2
As I continue working my way through the book on programming puzzles, I came across those involving permutations. In this post I’ll collect puzzles with the same theme, both from the book and from the internet.
All permutations
The first puzzle is to compute all the permutations of a given array. By extension, it can be used to compute all the permutations of a string, too, if we view it as an array of characters. To do this we’ll implement Heap’s algorithm. The following is its recursive version.
1 | def heap(permutations: list[list], A: list, n: int): |
The array permutations is the accumulator which will store all the permutations of the array. The initial arguments to the function would be an empty acuumulator, the list to permute, and the length of the list.
Next permutation
The next puzzle we’ll look at is computing the next permutation of the array in lexicographical order. The following implementation has been taken from the book.
1 | def next_permutation(perm: list[int]) -> list[int]: |
Previous permutation
A variation of the puzzle is to compute the previous permutation of the array in lexicographical order. The idea is to “reverse” the logic for computing the next permutation. If we look closely, we’ll find that all we’re changing are the comparison operators.
1 | def previous_permutation(perm: list[int]) -> list[int]: |
kth smallest permutation
The final puzzle we’ll look at is the one where we need to compute the k’th smallest permutation. The solution to this uses the previous_permutation function that we saw above. The idea is to call this function k times on the lexicographically-largest array. Sorting the array in decreasing order results is the largest. This becomes the input to the previous_permutation function.
1 | def kth_smallest_permutation(perm: list[int], k: int) -> list[int]: |
That’s it. These are puzzles involving permutations.
Programming Puzzles 1
I am working my way through a classic book of programming puzzles. As I work through more of these puzzles, I’ll share what I discover to solidify my understanding and help others who are doing the same. If you’ve ever completed puzzles on a site like leetcode, you’ll notice that the sheer volume of puzzles is overwhelming. However, there are patterns to these puzzles, and becoming familiar with them makes it easier to solve them. In this post we’ll take a look at one such pattern - two pointers - and see how it can be used to solve puzzles involving arrays.
Two Pointers
The idea behind two pointers is that there are, as the name suggests, two pointers that traverse the array, with one pointer leading the other. Using these two pointers we update the array and solve the puzzle at hand. As an illustrative example, let us consider the puzzle where we’re given an array of even and odd numbers and we’d like to move all the even numbers to the front of the array.
Even and Odd
1 | def even_odd(A: list[int]) -> None: |
The two pointers here are idx and write_idx. While idx traverses the array and indicates the current element, write_idx indicates the position where the next even number should be written. Whenever idx points to an even number, it is written at the position indicated by write_idx. With this logic, if all the numbers in the array are even, idx and write_idx point to the same element i.e. the number is swapped with itself and the pointers are moved forward.
We’ll build upon this technique to remove duplicates from the array.
Remove Duplicates
Consider a sorted array containing duplicate numbers. We’d like to keep only one occurrence of each number and overwrite the rest. This can be solved using two pointers as follows.
1 | def remove_duplicates(A: list[int]) -> int: |
In this solution, idx and write_idx start at index 1 instead of 0. The reason is that we’d like to look at the number to the left of write_idx, and starting at index 1 allows us to do that. Notice also how we’re writing the if condition to check for duplicity in the vicinity of write_idx; the number to the left of write_idx should be different from the one that idx is presently pointing to.
As a varitation, move the duplicates to the end of the array instead of overwriting them.
1 | def remove_duplicates(A: list[int]) -> None: |
As another variation, remove a given number from the array by moving it to the end.
1 | def remove(A: list[int], k: int) -> None: |
With this same pattern, we can now change the puzzle to state that we want at most two instances of the number in the sorted array.
Remove Duplicates Variation
1 | def remove_duplicates(A: list[int]) -> int: |
Akin to the previous puzzle, we look for duplicates in the vicinity of write_idx. While in the previous puzzle the if condition checked for one number to the left, in this variation we look at two positions to the left of write_idx to keep at most two instances. The remainder of the logic is the same. As a variation, try keeping at most three instances of the number in the sorted array.
Finally, we’ll use the same pattern to solve the Dutch national flag problem.
Dutch National Flag
In this problem, we sort the array by dividing it into three distinct regions. The first region contains elements less than the pivot, the second region contains elements equal to the pivot, and the third region contains elements greater than the pivot.
1 | def dutch_national_flag(A: list[int], pivot_idx: int) -> None: |
This problem combines everything we’ve seen so far about two pointers and divides the array into three distinct regions. As we compute the first two regions, the third region is computed as a side-effect.
We can now solve a variation of the Dutch national flag partitioning problem by accepting a list of pivot elements. In this variation all the numbers within the list of pivots appear together i.e. all the elements equal to the first pivot element appear first, equal to second pivot element appear second, and so on.
1 | def dutch_national_flag(A: list[int], pivots: list[int]) -> None: |
That’s it, that’s how we can solve puzzles involving two pointers and arrays.
Creating a realtime data platform with Pinot, Airflow, Trino, and Debezium
I’d previously written about creating a realtime data warehouse with Apache Doris and Debezium. In this post we’ll see how to create a realtime data platform with Pinot, Trino, Airflow, Debezium, and Superset. In a nutshell, the idea is to bring together data from various sources into Pinot using Debezium, transform it using Airflow, use Trino for query federation, and use Superset to create reports.
Before We Begin
My setup consists of Docker containers for running Pinot, Airflow, Debezium, and Trino. Like in the post on creating a warehouse with Doris, we’ll create a person table in Postgres and replicate it into Kafka. We’ll then ingest it into Pinot using its integrated Kafka consumer. Once that’s done, we’ll use Airflow to transform the data to create a view that makes it easier to work with it. Finally, we can use Superset to create reports. The intent of this post is to create a complete data platform that makes it possible to derive insights from data with minimal latency. The overall architecture looks like the following.
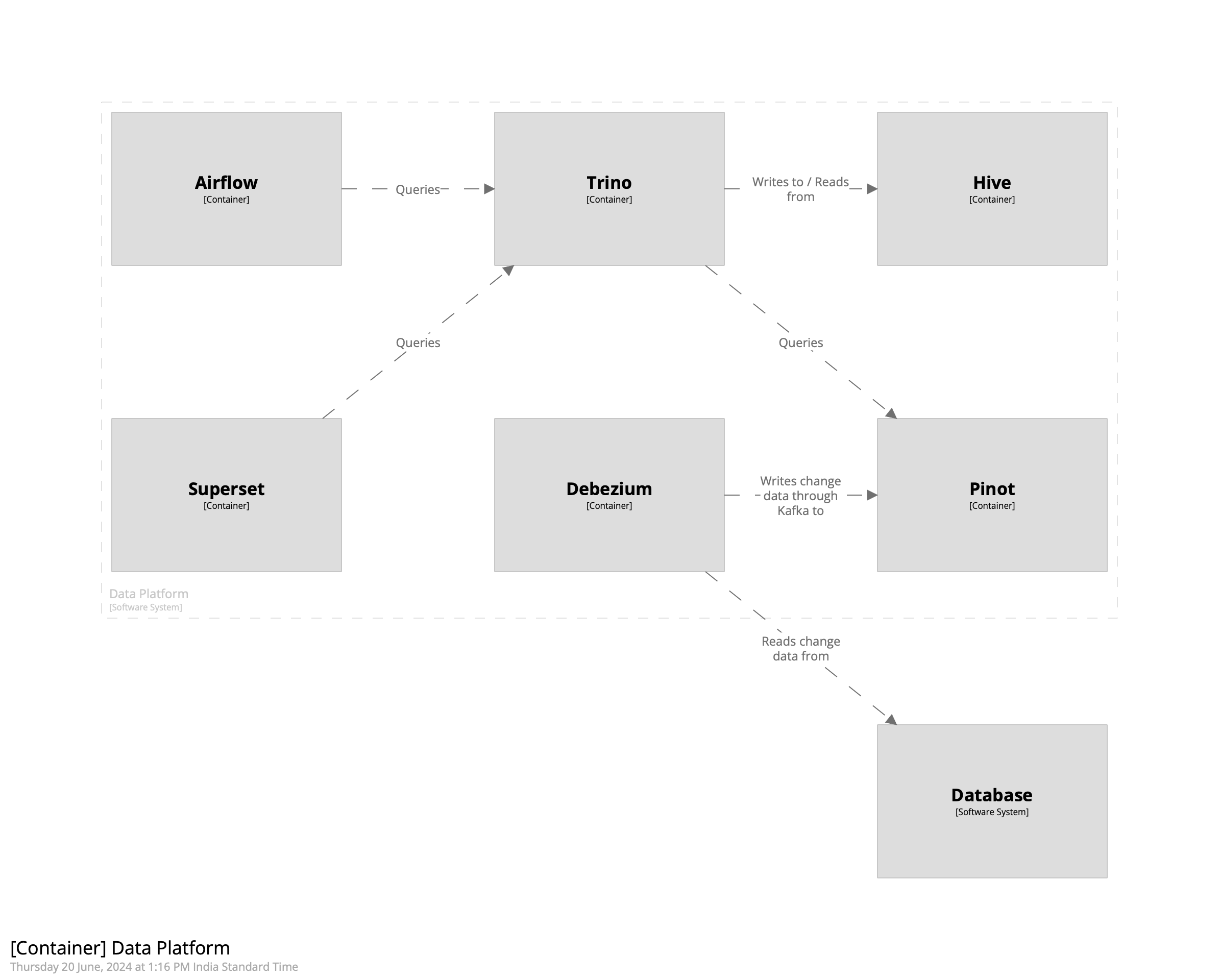
Getting Started
We’ll begin by creating a schema for the person table in Pinot. This will then be used to create a realtime table. Since we want to use Pinot’s upsert capability to maintain the latest record of each row, we’ll ensure that we define the primary key correctly in the schema. In the case of the person table, it is the combination of the id and the customer_id field. The schema looks as follows.
1 | { |
We’ll use the schema to create the realtime table in Pinot. Using ingestionConfig we’ll extract fields out of the Debezium payload and into the columns defined above. This is defined below.
1 | "ingestionConfig":{ |
Next we’ll create a table in Postgres to store the entries. The SQL query is given below.
1 | CREATE TABLE person ( |
Next we’ll create a Debezium source connector to stream change data into Kafka.
1 | { |
Finally, we’ll use curl to send these configs to their appropriate endpoints, beginning with Debezium.
1 | curl -H "Content-Type: application/json" -XPOST -d @debezium/person.json localhost:8083/connectors | jq . |
To create a table in Pinot we’ll first create the schema followed by the table. The curl command is given below.
1 | curl -F schemaName=@tables/001-person/person_schema.json localhost:9000/schemas | jq . |
The command to create the table is given below.
1 | curl -XPOST -H 'Content-Type: application/json' -d @tables/001-person/person_table.json localhost:9000/tables | jq . |
With these steps done, the change data from Debezium will be ingested into Pinot. We can view this using Pinot’s query console.
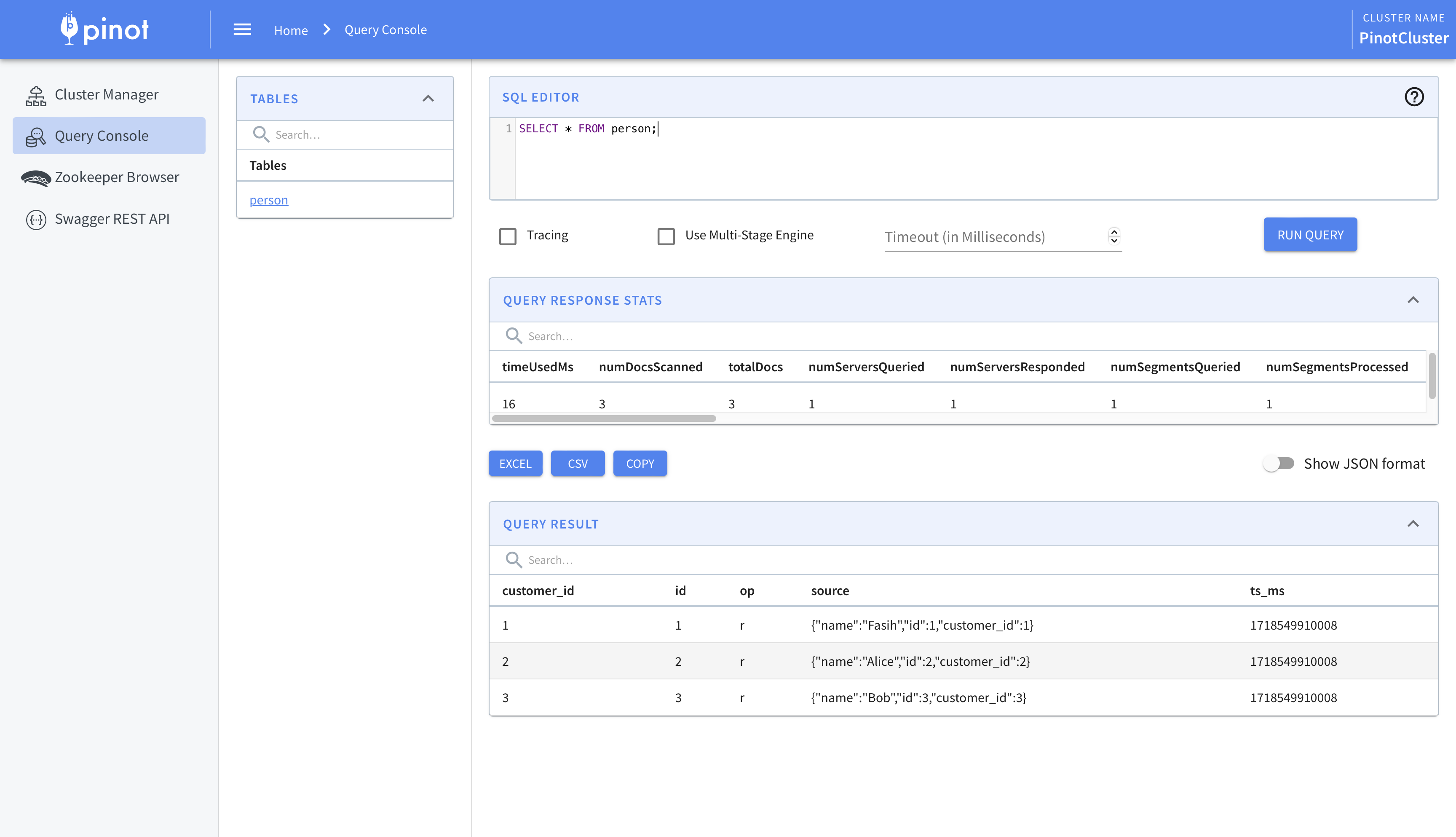
This is where we begin to integrate Airflow and Trino. While the data has been ingested into Pinot, we’ll use Trino for querying. There are two main reasons for this. One, this allows usto federate queries across multiple sources. Two, Pinot’s SQL capabilities are limited. For example, there is no support, as of writing, for creating views. To circumvent these we’ll create a Hive connector in Trino and use it to query Pinot.
The first step is to connect Trino and Pinot. We’ll do this using the Pinot connector.
1 | CREATE CATALOG pinot USING pinot |
Next we’ll create the Hive connector. This will allow us to create views, and more importantly materialized views which act as intermediate datasets or final reports, which can be queried by Superset. I’m using AWS Glue instead of Hive so you’ll have to change the configuration accordingly.
1 | CREATE CATALOG hive USING hive |
We’ll create a schema to store the views and point it to an S3 bucket.
1 | CREATE SCHEMA hive.views |
We can then create a view on top of the Pinot table using Hive.
1 | CREATE OR REPLACE VIEW hive.views.person AS |
Finally, we’ll query the view.
1 | trino> SELECT * FROM hive.views.person; |
While this helps us ingest and query the data, we’ll take this a step further and use Airflow to create the views instead. This allows us to create views which are time-constrained. For example, if we have an order table which contains all the orders placed by the customers, using Airflow allows to create views which are limited to, say, the last one year by adding a WHERE clause.
We’ll use the TrinoOperator that ships with Airflow and use it to create the view. To do this, we’ll create an sql folder under the dags folder and place our query there. We’ll then create the DAG and operator as follows.
1 | dag = DAG( |
Workflow
The kind of workflow this setup enables is the one where the data engineering team is responsible for ingesting the data into Pinot and creating the base views on top of it. The business intelligence / analytics engineering, and data science teams can then use Airflow to create datasets that they need. These can be created as materialized views to speed up reporting or training of machine learning models. Another advantage of this setup is that bringing in older data, say, of the last two years instead of one, is a matter of changing the query of the base view. This avoids complicated backfills and speeds things up significantly.
As an aside, it is possible to use DBT instead of TrinoOperator. It can be used in conjunction with TrinoOperator, too. However, I preferred using the in-built operator to keep the stack simpler.
Cost
Before we conclude, we’ll quickly go over how to keep the cost of the Pinot cluster low while using this setup. In the official documentation it says that data can be seperated by age; older data can be stored in HDDs while the newer data can be stored in SSDs. This allows lowering the cost of the cluster.
An alternative approach is to keep all the data in HDDs and load subsets into Hive for querying. This also allows changing the date range of the views by simply updating the queries. In essence, Pinot becomes the permanent storage for data while Trino and Hive become the intermediate query and storage layer.
That’s it. That’s how we can create a realtime data platform using Pinot, Trino, Debezium, and Airflow.
A note on exponents
In the chapter on exponents the authors mention that if a base is raised to both a power and a root, we should calculate the root first and then the power. This works perfectly well. However, reversing the order produces correct results, too. In this post we’ll see why that works using the properties of exponents.
Let’s say we have a base
Let’s take a look at a numerical example. Consider
Therefore, we can apply the operations in any order.