In the previous post we looked at how JVM generates assembly code and how we can take a look at it. In this post we will look at yet another optimization technique called loop unrolling.
What is loop unrolling?
To quote The Java HotSpot Performance Engine Architecture,
the Server VM features loop unrolling, a standard compiler optimization that enables faster loop execution. Loop unrolling increases the loop body size while simultaneously decreasing the number of iterations.
Okay so it is an optimization that makes our loops faster by increasing the body size, and reducing the iterations. This is much better explained by example.
A loop like this:
1 | for(int i = 0; i < N; i++) { |
can be unrolled into this:
1 | for(int i = 0; i < N; i += 4) { |
So the size of the loop has increased because instead of calling method S just once per iteration, we call it 4x. The iterations have reduced because we now have a stride of 4 (i += 4). This is a space-time tradeoff because you gain speed by increasing the size of the program. If this for loop were to be a part of a hot method that got compiled to assembly, more code cache would be consumed because of unrolling.
Loop unrolling, however, wins at a different front — speed. By increasing the stride of the loop, we’re reducing the number of jumps that the CPU has to make. Jumps are costly and a reduction in jumps is a huge performance boost.
Loop unrolling in action
1 | import org.openjdk.jmh.annotations.*; |
The code above is a JMH benchmark which will fork 1 JVM (@Fork), warm it for 10 iterations (@Warmup), then run our benchmark for 5 iterations (@Measurement). The generated assembly looks like this:
1 | 0x00000001296ac845: cmp %r10d,%ebp |
So the first block of code is moving 0x42 to some memory location (line #3), incrementing the counter %ebp (line #4), and jumping back to the start of the loop for the next iteration (line #6). Then there is the second block which increments the counter by 4 (line #11) and uses vmovdqu (line #10).
In the second block, vmovdqu moves %xmm0 (a 128-bit register) to some memory location (line #10) i.e. we’re writing 4 32-bit numbers in one go. This is equivalent of writing nums[0 .. 3] in one iteration.
This means that our entire loop which writes 10 array elements will not run for 10 iterations at all. It will run for 4 — 2 iterations to write 8 elements in groups of 4 each (block 2), and 2 more to write the remaining 2 elements (block 1).
What we saw above was loop unrolling to enable vectorization. Since this happened without any effort on our part, it’s called auto-vectorization.
What is vectorization?
There are certain CPU instructions which are capable of operating on multiple data elements simultaneously. Such instructions are called SIMD instructions — Single Instruction Multiple Data or vectorized instructions. In the example above, all 4 elements were packed into a single register XMM0 and then moved to their memory location with vmovdqu. This results in faster processing by saving jumps and clock cycles.
1 | +--------|--------|--------|--------+ |
Auto-vectorization is when the compiler converts the scalar instructions (which operate on a single data element at a time) to vector instructions (which operate on multiple data elements at a time) without any effort on the part of the programmer.
Vectorizing the code enables superword level parallelism (SLP). SLP is a type of SIMD parallelism in which source and result operands are packed in a storage location.
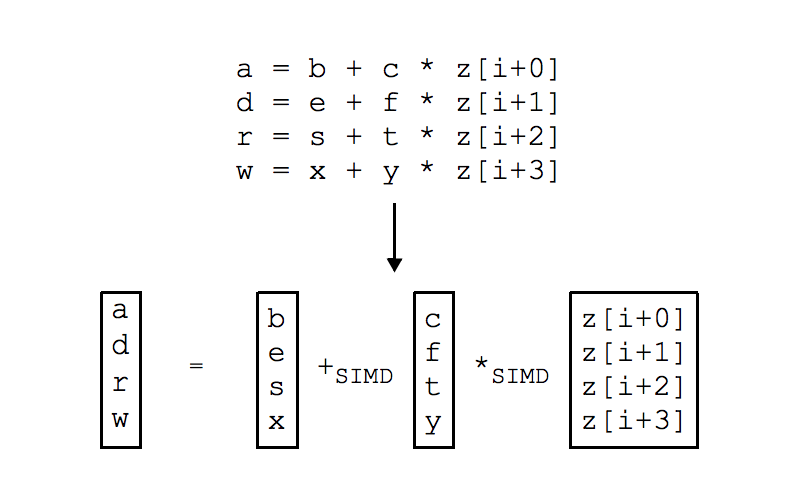
The example shows statement packing in which the operands have been packed into registers and the scalar addition and multiplication have been replaced by their vectorized counterparts.
How does loop unrolling enable SLP?
Consider this loop:
1 | for (i=0; i<16; i++) { |
This is a loop containing isomorphic statements — statements that contain same operations in the same order. Such statements are easy to unroll. So the loop above can be transformed as follows:
1 | for (i=0; i<16; i+=4) { |
This can be further transformed as:
1 | for (i=0; i<16; i+=4) { |
Now it becomes easy to see how SLP can be used to speed up the execution of the loop. Loop unrolling sets the stage for SLP.
Which flags control loop unrolling and SLP?
There are a couple of flags - -XX:LoopUnrollLimit and -XX:+UseSuperWord. LoopUnrollLimit controls how many times your loop will be unrolled and UseSuperWord controls the transformation of scalar operations into vectorized operations.
Conclusion
Loop unrolling makes your code faster by doing more per iteration and increasing the stride. It’s a space-time trade off where you make your code larger so that the execution takes less time. Loop unrolling can be taken a step further to make scalar instructions into vector instructions. These instructions operate on packed data and achieve more per instruction than their scalar counterparts.
The conversion from scalar instructions to vector instructions is called vectorization. Since this happens transparently to the programmer, it is called auto-vectorization.
Recommended reading
There are a few blog posts that I recommend you read.
A fundamental introduction to x86 assembly programming
This post provides a brief introduction to x86 assembly programming. Having studied assembly programming in university a long time ago, the post is quick refresher on the basic concepts of assembly programming like addresing modes, registers, etc. I keep it handy and refer to it when I have to read the assembly code generated by JVM.
JMH - Java Microbenchmark Harness
This post provides a brief introduction to JMH (Java Mirobenchmark Harness). What does JMH do?
JMH is a Java harness for building, running, and analysing nano/micro/milli/macro benchmarks written in Java and other languages targetting the JVM.
The post will show you how to write a simple benchmark, how to avoid common pitfalls, etc. It is a good read regardless of this series for two reasons: one, microbenchmarking is coming to Java 9 out-of-the-box and two, microbenchmarking is hard to get right.
Exploiting Superword Level Parallelism with Multimedia Instruction Sets
This is the research paper on superword level parallelism. I’ve borrowed examples and diagrams from this paper. The paper will introduce you to what SLP is, and also provide an algorithm on how to find parts of code which are amenable to SLP.