In the previous post we saw how we can embed a Superset dashboard in a webpage using a Flask app. In this post we’ll look at creating indexes on the tables that are stored in Pinot. We’ll look at the various types of indexes that can be created and then create indexes of our own to speed up the queries.
Getting started
Very briefly, a database index is a data structure that improves retrieving data from the tables. It is used to quickly find the rows that we’re interested in without having to scan the entire table. Pinot supports different types of indexes that can be used to speed up different types of queries. Knowing the access patterns of the queries helps us decide which indexes we’d like to create. We’ll quickly look at each type of index that Pinot provides, write a few queries, and then create indexes to speed them up. Let’s start by looking at the various index types that are available in Pinot.
Pinot supports the following types of indexes — bloom filter index, forward index, FST index, geospatial index, inverted index, JSON index, range index, star-tree index, text search index, and timestamp index. In the sections that follow, we’ll look at how to create an inverted index, and a range index to speed up our queries. Let’s start with the inverted index.
Let’s say we’d like to find out the sum of the amounts of orders placed on January 1st. One way to write this query would be to convert the created_at time to a date on the fly. This would require us to look at every row we have in the table and compare it against the date we’re looking for. Another way to write this query would be to convert created_at to a date during ingestion time and create an inverted index on it. Creating an inverted index would store a mapping of each date to the row IDs with the same date. This will enable us to filter only those rows which have the date we’re looking for instead of having to look at each one of them.
We’d have to update our table and schema for the orders table. We’ll start by adding a column to our schema definition which will store the date as a string.
1 | { |
Next, we’ll convert the created_at time to a date and store it in the date column. To do this, we’ll create a field-level transformation in the table definition.
1 | { |
Next, we’ll enable the inverted index on the date column by adding the following to the table definition.
1 | { |
Once we PUT these configs, we’ll reload the segments so that the index is created. We can now write our query in the Pinot console.
1 | SELECT "date", SUM(amount) as total |
We can verify that the index was used by looking at the explain plan for the query.
1 | EXPLAIN PLAN FOR |
This produces the following result.
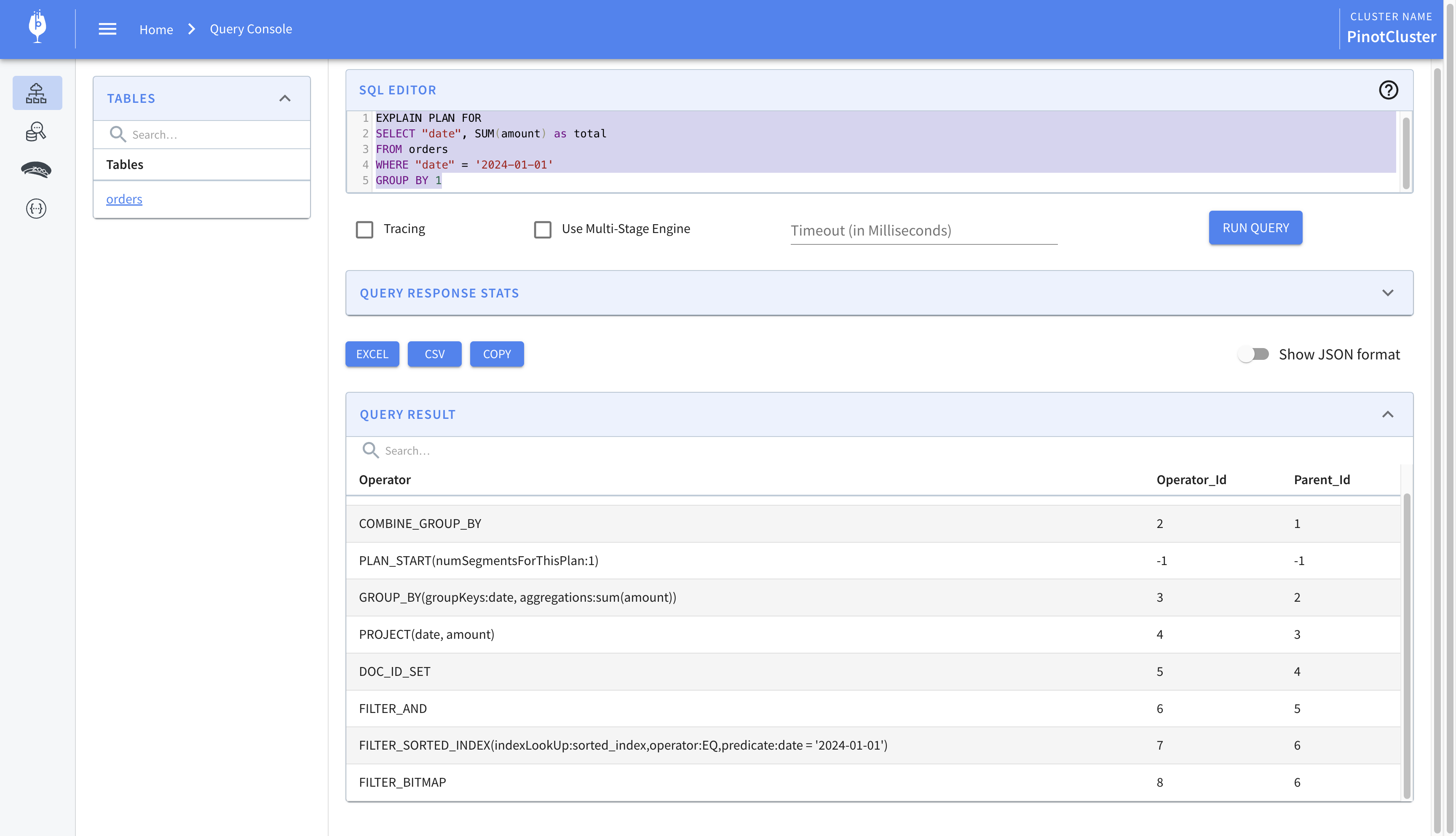
Looking at the explain plan, we find the following line. It tells us that the index was used to look up the date ‘2024-01-01’
1 | FILTER_SORTED_INDEX(indexLookUp:sorted_index,operator:EQ,predicate:date = '2024-01-01') |
Let’s modify the query slightly and look for the daily total for the last 90 days. It looks as follows.
1 | SELECT "date", SUM(amount) as total |
The ago() function takes as argument a duration string and returns milliseconds since epoch. We compare it against created_at, which is also expressed as milliseconds since epoch, to get the final result. Let’s look at the explain plan for the query.
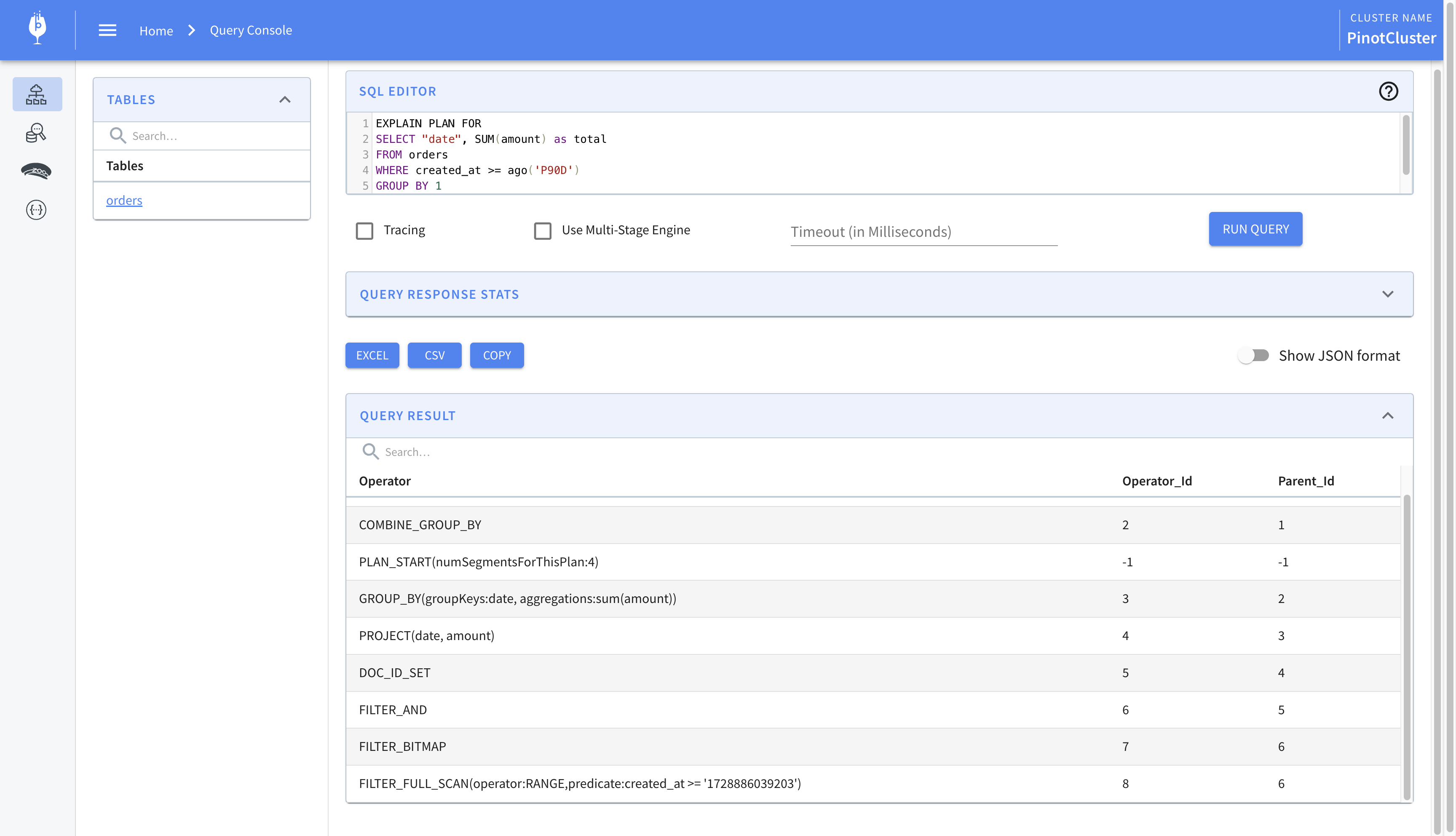
We find the following line which indicates that an index was not used.
1 | FILTER_FULL_SCAN(operator:RANGE,predicate:created_at >= '1728886039203') |
We can improve the performance of the query by using a range index which allows us to efficiently query over a range of values. This helps us speed up queries which involve comparison operators like less than, greater than, etc. To create a range index, we’ll have to update the table definition and specify the column on which we’d like to create the index. We’ll add the following to the table definition.
1 | { |
Like we did previously, we’ll PUT this config and reload the segments. We’ll once again look at the explain plan for the query above.
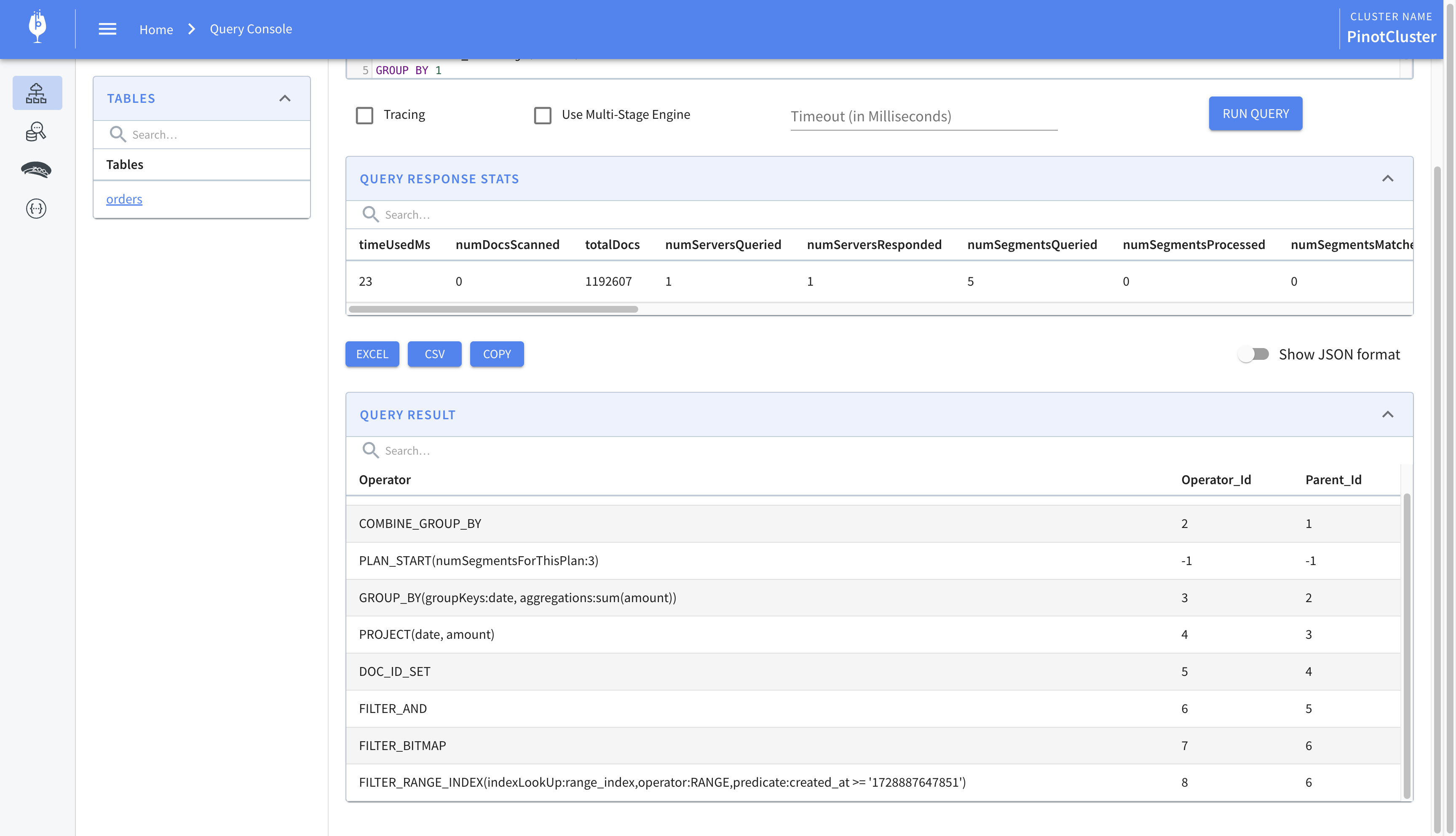
We now find the following line which indicates that the range index was used.
1 | FILTER_RANGE_INDEX(indexLookUp:range_index,operator:RANGE,predicate:created_at >= '1728887647851') |
This was a quick overview of using indexes to speed up queries on Pinot. We looked at the inverted index and the range index. In the next post, we’ll look at the star-tree index which lets us compute pre-aggregations on columns and speeds up the result of operations like SUM and COUNT. We’ll also look at stream processing to generate new events from the ones emitted by Debezium.