In the previous post we looked at how to query Pinot. We queried it using its REST API, the console, and Trino. In this post we’re going to look at how to use Apache Airflow to periodically create datasets on top of the data that’s been stored in Pinot. Creating datasets allows us to reference them in data visualization tools for quicker rendering. We’ll leverage Trino’s query federation to store the resultant dataset in S3 so that it can be queried using the Hive connector.
Getting started
Let’s say that the marketing team wants to run email campaigns where the users who actively place orders are given a promotional discount. The dataset they need contains the details of the user like their name and email so that the communication sent out can be personalised. We can write the following query in the source Postgres database to see what the dataset would look like.
1 | SELECT |
This gives us the following result.
1 | | id | first_name | email | count | |
For us to create this dataset using Trino, we’ll have to ingest the user table into Pinot. Like we did in the earlier posts, we’ll use Debezium to stream the rows. We’ll skip repeating the steps here since we’ve already seen them. Instead, we’ll move to writing the query in Trino. Once we’ve written the query, we’ll look at how to use Airflow to run it periodically. I’ve also updated the orders table to extract the user_id column out of the source payload. Let’s translate the query written for Postgres to Trino.
1 | SELECT u.id, |
We saw earlier that we’d like to save the result of this query so that the marketing team could use it. We can do that by storing the results in a table created using the above SELECT statement. Let’s create a schema in Hive called datasets where we’ll store the results. The following query creates the schema.
1 | CREATE SCHEMA hive.datasets |
We can now create the table using the above SELECT statement.
1 | CREATE TABLE hive.datasets.top_users AS |
We can now query the table using the query that follows.
1 | SELECT * |
Having seen how to create datasets as tables using Trino CLI, let’s see how we can do the same using Airflow. Let’s say that the marketing team requires the data to be regenerated everyday. We can schedule an Airflow DAG to run daily to recreate this dataset. Briefly, Airflow is a task orchestrator. An orchestrator allows creating and executing workflows expressed as directed acyclic graphs (DAGs). Each workflow consists of multiple tasks, which form the nodes in the graph, and edges between the tasks indicate the directionality.
We’ll create a workflow which recreates the dataset daily. In a nutshell, the workflow first drops the older table and then recreates a newer one. This is because the Trino connector does not allow creating or replacing table as an atomic operation. We’ll leverage Airflow’s SQL operator and templating mechanism to create and execute queries. The following shows the files and folders we’ll be working with as we create the DAG.
1 | $ tree airflow/dags |
Let’s begin with the drop_table.sql query. This is a templated query which allows dropping a table. Writing queries as templates allows us to leverage the Jinja2 templating engine that comes with Airflow. We can create queries depending on the parameters passed to the operator. This allows reusing the same template across multiple tasks. The variables are enclosed in two pairs of braces and the name of the variable is written between them. The content of the file is shown below.
1 | DROP TABLE IF EXISTS {{ params.name }} |
As we’ll see shortly, we’ll pass parameters to the Airflow task executing this query which are available in the params dictionary in the template. In the query above, we’d have to pass the name variable which contains the name of the table we’d like to drop. The top_users.sql file contains the same query we’ve seen above so we’ll move on to setting up the DAG.
The DAG is written in the file create_top_users_dataset.py and contains two tasks. First, to drop the table, which uses the templated query above. Second, to create the dataset. Both of these tasks use the SQLExecuteQueryOperator. Its parameters include a connection ID, which is used to connect to the database, the path to the SQL file containing the templated query to execute, and the values for the parameters. The contents of the file are shown below.
1 | import pendulum |
We define the DAG in line 6 and specify that it will execute daily. Line 13 and 21 define the tasks within the DAG. The first task drops the table, if it exists. The second task creates the table again. On line 29 we define the relationship between the tasks. Both of the tasks are of type SQLExecuteQueryOperator. This task allows executing arbitrary SQL queries by connecting to a database. The connection to the database is specified as the conn_id; we’ve specified it as trino. As we’ll see next, we need to create the connection using the Airflow console. Once we create the connection, we can execute the DAG.
Airflow UI is available on http://localhost:8080. From there we’ll click on ‘Admin’ up top, and then ‘Connections’. From there we’ll click on the ‘+’ icon to create a connection. The screenshot below shows what we need to fill in to make the connection. In my setup, Trino runs with the hostname trino and you’ll have to replace this to match what you have. Once the details are entered, we’ll click the ‘Save’ button at the bottom to create the connection.
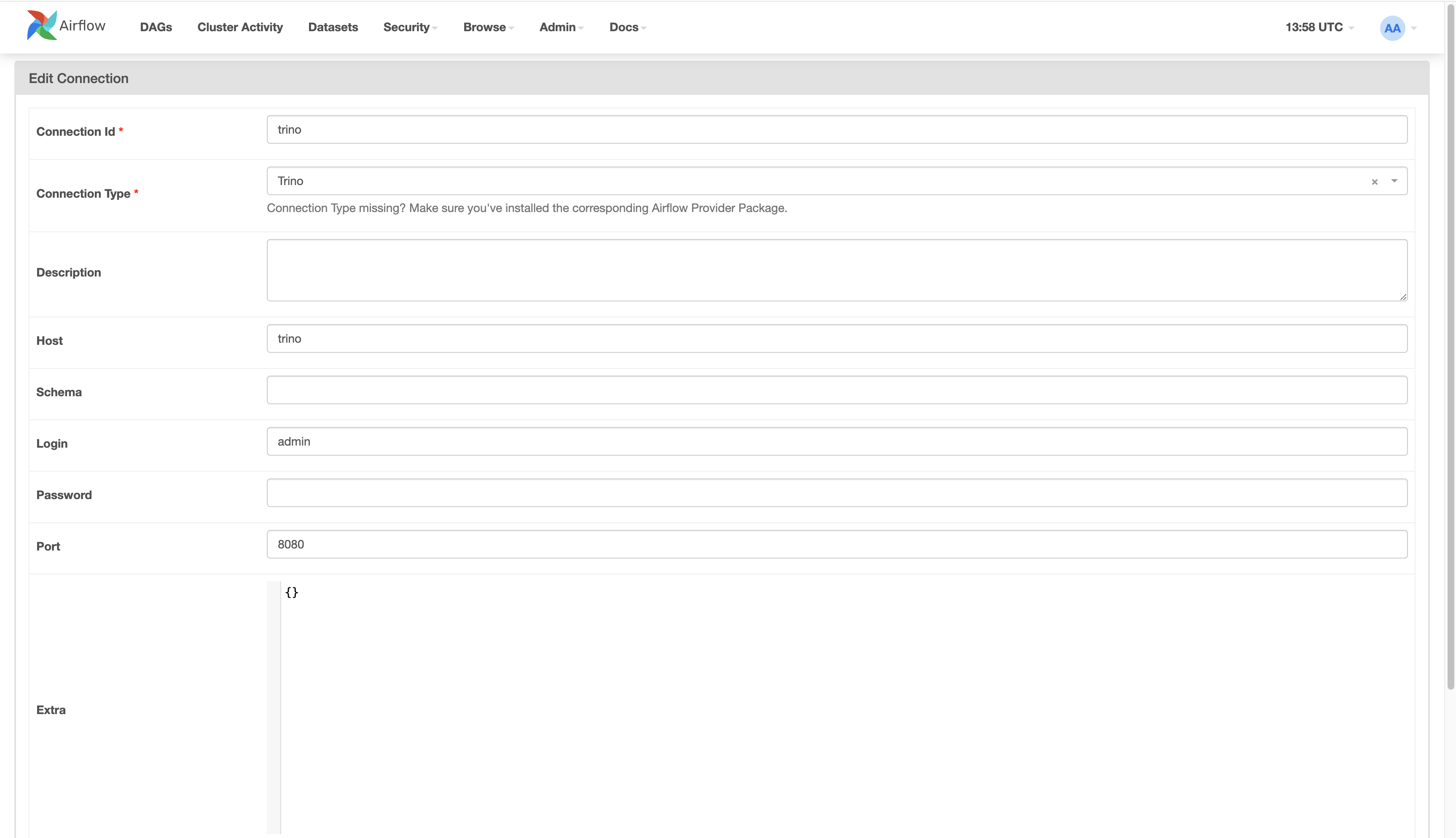
Finally, we can trigger the DAG. We’ll click on the ‘DAGs’ option on top left side of the screen. This will show us the list of DAGs available. From there, we’ll click the play button for the create_daily_datsets DAG. This will trigger and run the DAG. We’ll wait for the DAG to finish running. Assuming everything works correctly, we will have created a table in S3. Leaving the DAG in the enabled state causes it to run on the specified schedule; in this case it is daily. As the DAG continues to run, it’ll create and recreate the table daily.
That’s it on orchestrating tasks to create datasets on top of Pinot.