In the previous post we looked at evolving the schema. We briefly discussed handling null values in columns when we added the user_agent column. It allows null values since enableColumnBasedNullHandling is set to true. However, we weren’t able to see nullability in action since that column always had values in it. In this post we’ll evolve the schema one more time and add columns that have null values in them. We’ll see how to handle null values in Pinot queries, and how they differ from nulls in other databases. Let’s dive right in.
Getting started
We’ll begin by looking at the source payload that we’ve stored in Pinot.
1 | { |
In the payload above, we notice that there’s created_at but no updated_at or deleted_at. That’s because these have null values in the source table in Postgres. Let’s update the schema and table definitions to store these fields.
To update the schema, we’ll add the following to dateTimeFieldSpecs.
1 | { |
In the JSON above, we specify the usual fields just as we did for created_at. We also set defaultNullValue. This value will be used instead of null when these fields are extracted from the source payload. This is different from what you’d usually observe in a database that supports null values. The reason for this is that Pinot uses a forward index to store the values of each column. This index does not support storing null values and instead requires that a value be provided which will be stored in place of null. In our case, we’ve specified -1. The value that we specify as a default must be of the same data type as the the column. Since the two fields are of type LONG, specifying -1 suffices.
We’ll PUT this schema using the following curl command.
1 | curl -XPUT -F schemaName=@tables/002-orders/orders_schema.json localhost:9000/schemas/orders | jq . |
Next, we’ll update the table definition by adding a couple of field-level transformations.
1 | { |
And POST it using the following curl command.
1 | curl -XPUT -H 'Content-Type: application/json' -d @tables/002-orders/orders_table.json localhost:9000/tables/orders | jq . |
Like we did last time, we’ll reload all the segments using the following curl command.
1 | curl -XPOST localhost:9000/segments/orders/reload | jq . |
Now when we open the query console, we’ll see the table with updated_at and deleted_at fields with their values set to -1.
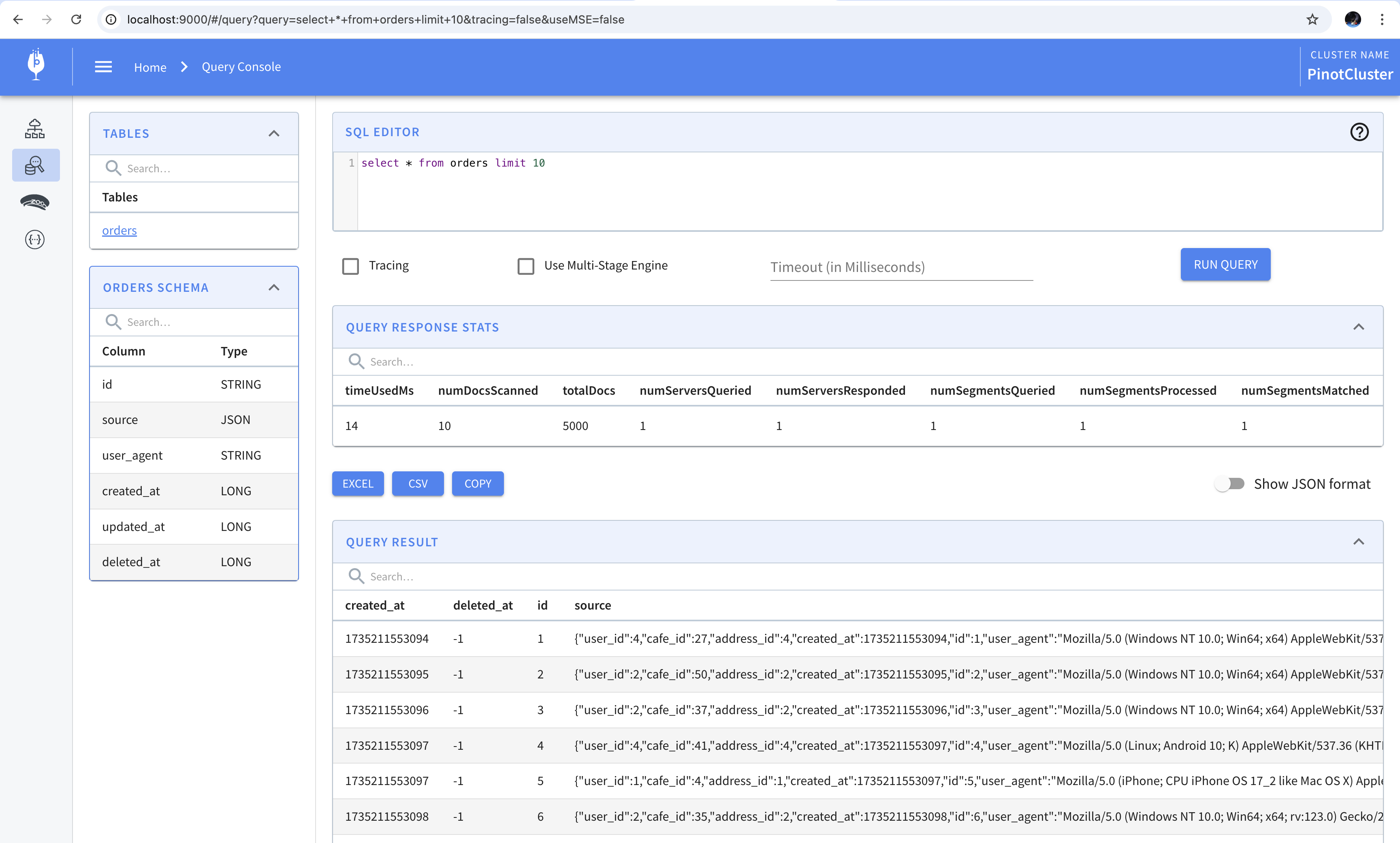
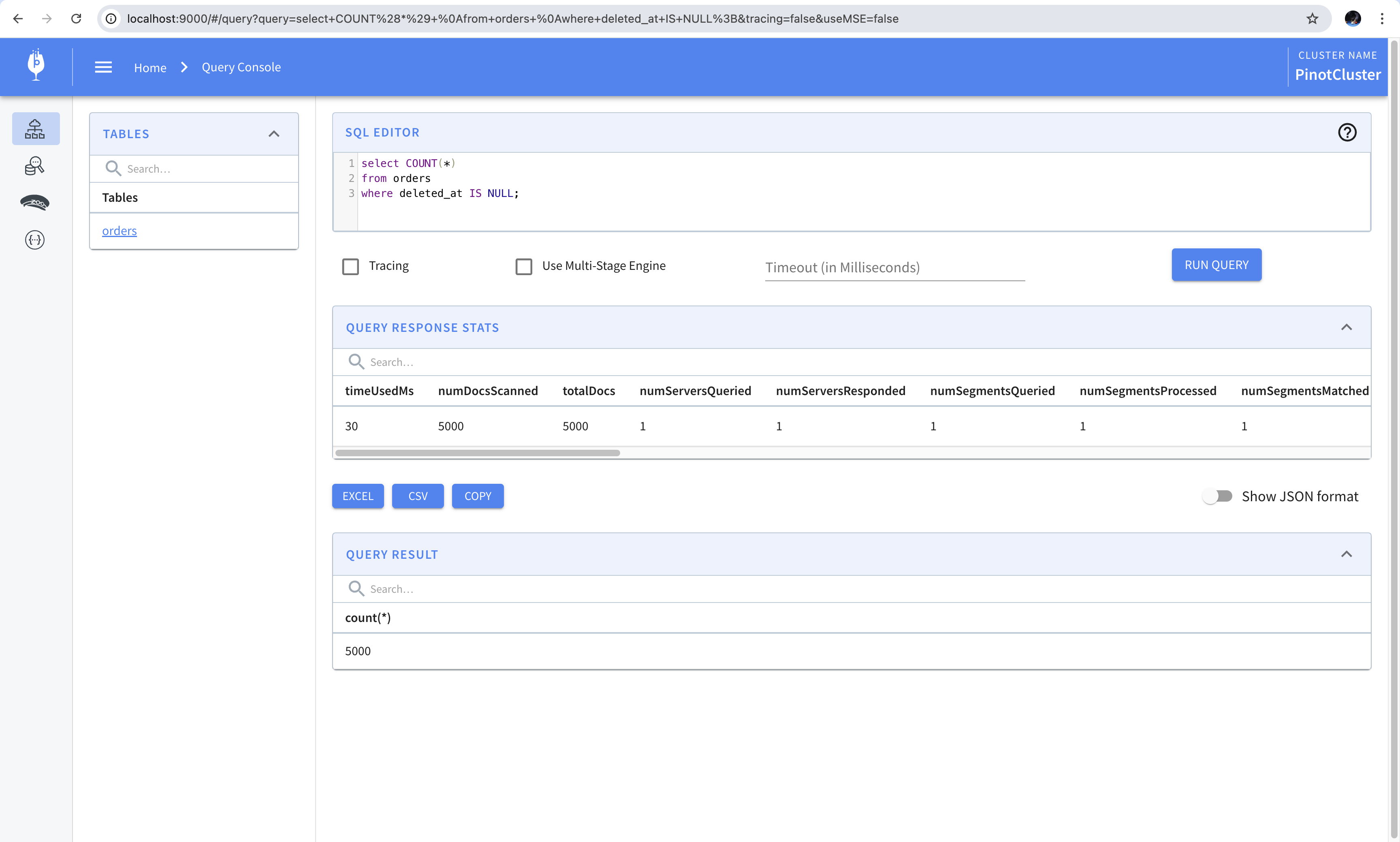
We know that we have a total of 5000 rows where the deleted_at field is set to null. This can be verified by running a count query in Pinot. This shows that although the values in the column are set to -1, Pinot identifies them as null and returns the correct result.
1 | SELECT COUNT(*) |
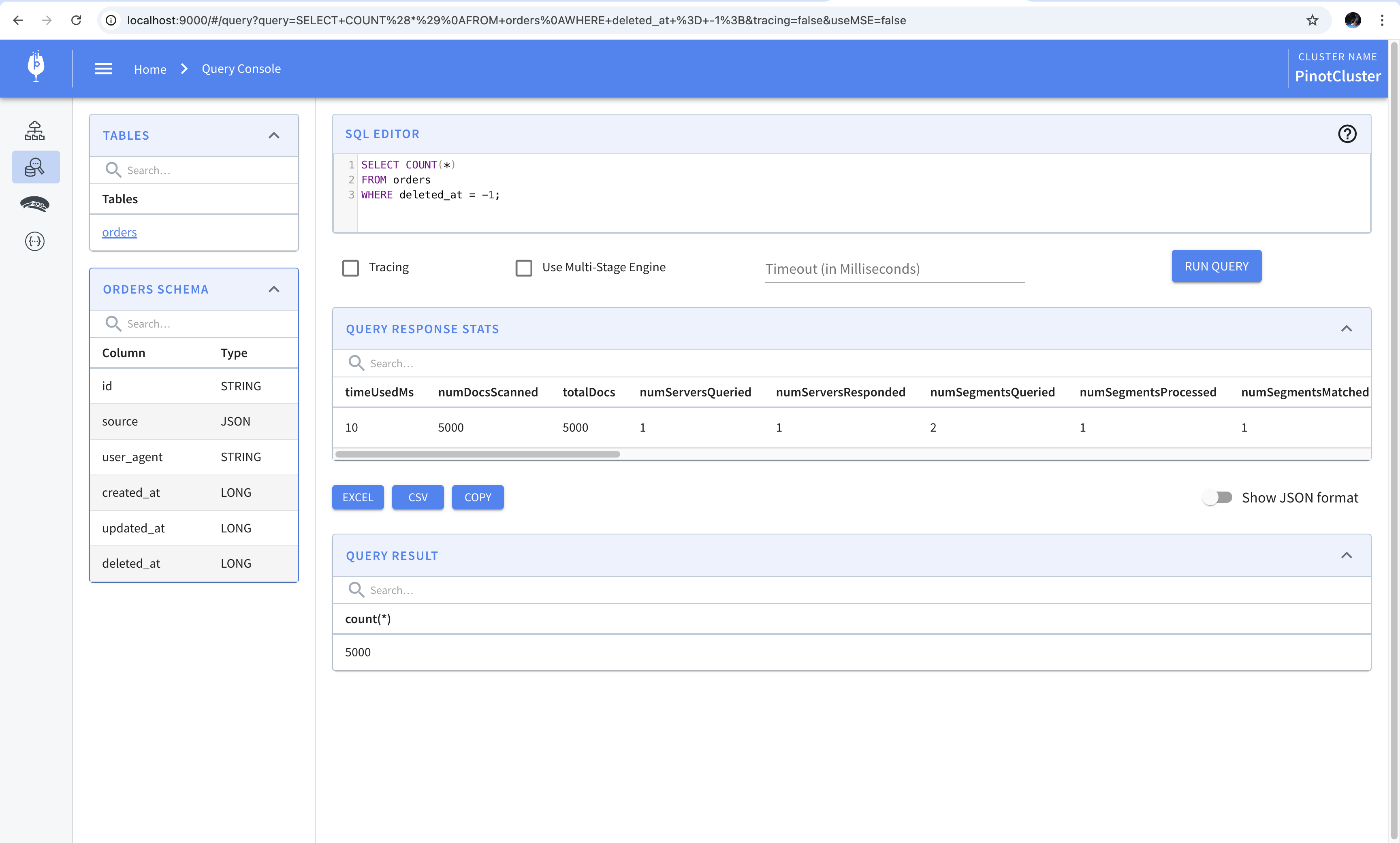
A workaround suggested in the documentation is to use comparison operators to compare against the value used in place of null. For example, the following query will produce the same result as the one shown above.
1 | SELECT COUNT(*) |
That’s it on how to handle null values in Pinot.