In the previous post we saw how to ingest the data into Pinot using Debezium. In this post we’re going to see how to evolve the schema of the tables stored in Pinot. We’ll begin with a simple query which computes an aggregate on the user agent column stored within the source payload. Then, we’ll extract the value of user agent column out of the source payload into a column of its own.
Getting started
Let’s start with a simple query. Let’s count the number of times each user agent appears in the table and sort it in descending order. We can do this using the following SQL query.
1 | SELECT JSON_EXTRACT_SCALAR(source, '$.user_agent', 'STRING', '...') AS user_agent, |
The result of running this query is shown below.
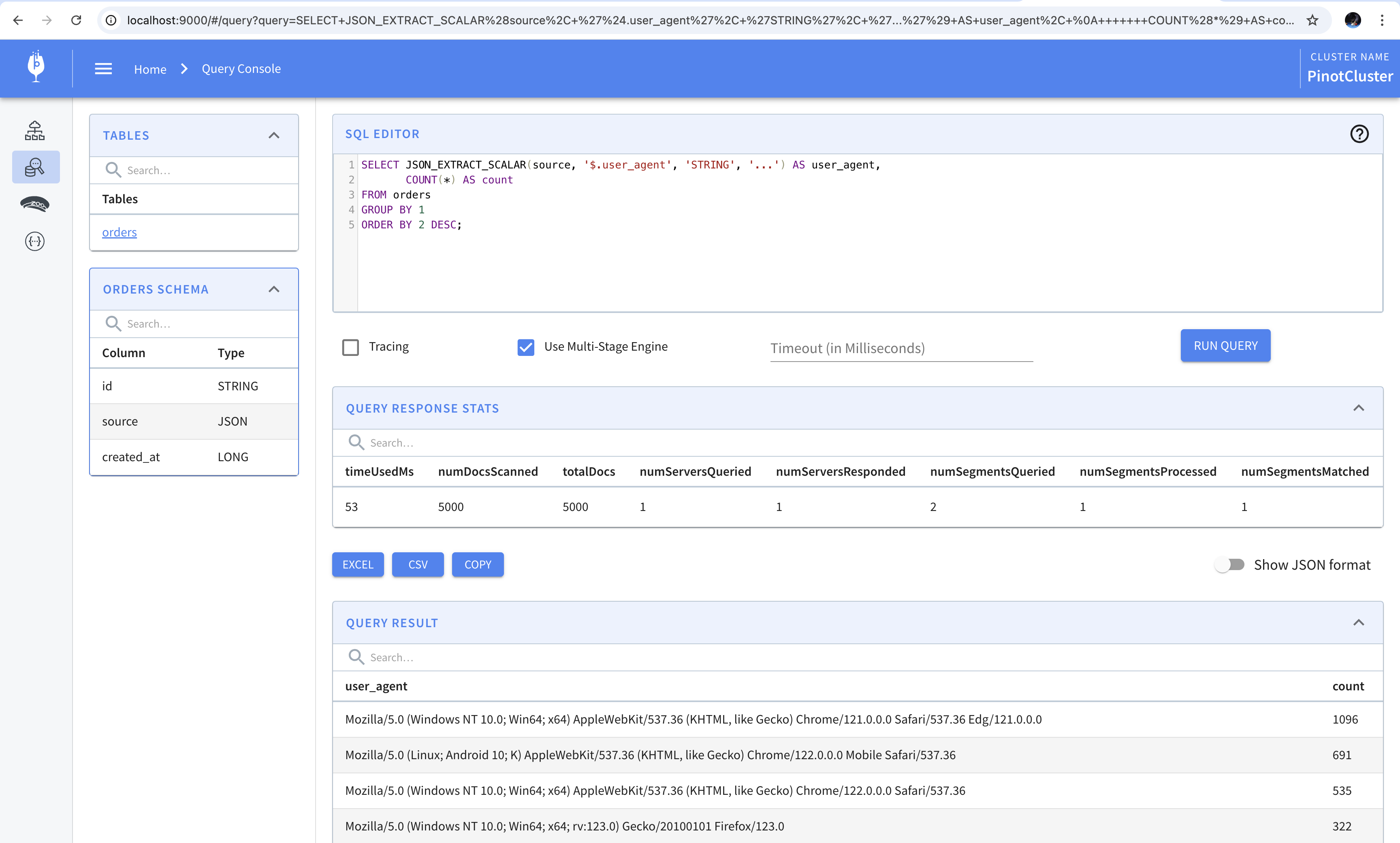
Let’s take a closer look at the query. To extract values out of the source column, we use the JSON_EXTRACT_SCALAR() function. It takes the name of the column containing the JSON payload, the path of the value within the payload, the datatype of the value returned, and the value to be used as a replacement for null.
For a simple query like this, using JSON_EXTRACT_SCALAR() works. However, it becomes unwieldy when there are more than one column to extract or when writing ad-hoc business analytics queries that join multiple tables on values present within a JSON column. Writing SQL would be easier if we could extract the value out of the JSON payload into a column of its own.
To extract the values out of the source payload into its own column, we’ll have to update the schema and table definitions. We’ll update the schema definition to add new columns, and we’ll update the table definition to extract fields out of the source column using field-level transformations.
Let’s begin by updating the schema.
1 | { |
We’ve added user_agent as a new column under dimensionFieldSpecs. Notice that we’ve set enableColumnBasedNullHandling to true. This allows columns to store null values in them. In Pinot, allowing or disallowing null values is configured per-table. The recommended way is to use column-based null handling where each column is configured to allow or disallow null values. This is what we’ve used in our schema above. The id, source, and created_at columns do not allow null values in them since they have notNull set to true. The user_agent column allows null values in it since it is implicitly nullable.
We’ll PUT the updated schema using curl.
1 | curl -XPUT -F schemaName=@tables/002-orders/orders_schema.json localhost:9000/schemas/orders | jq . |
Upon opening the query console we find that there’s an error message. This message indicates that the segments are invalid because they were created using an older version of the schema. We can reload all the segments to fix this error but we’ll get to that in a minute. We’ll first update the table definition.
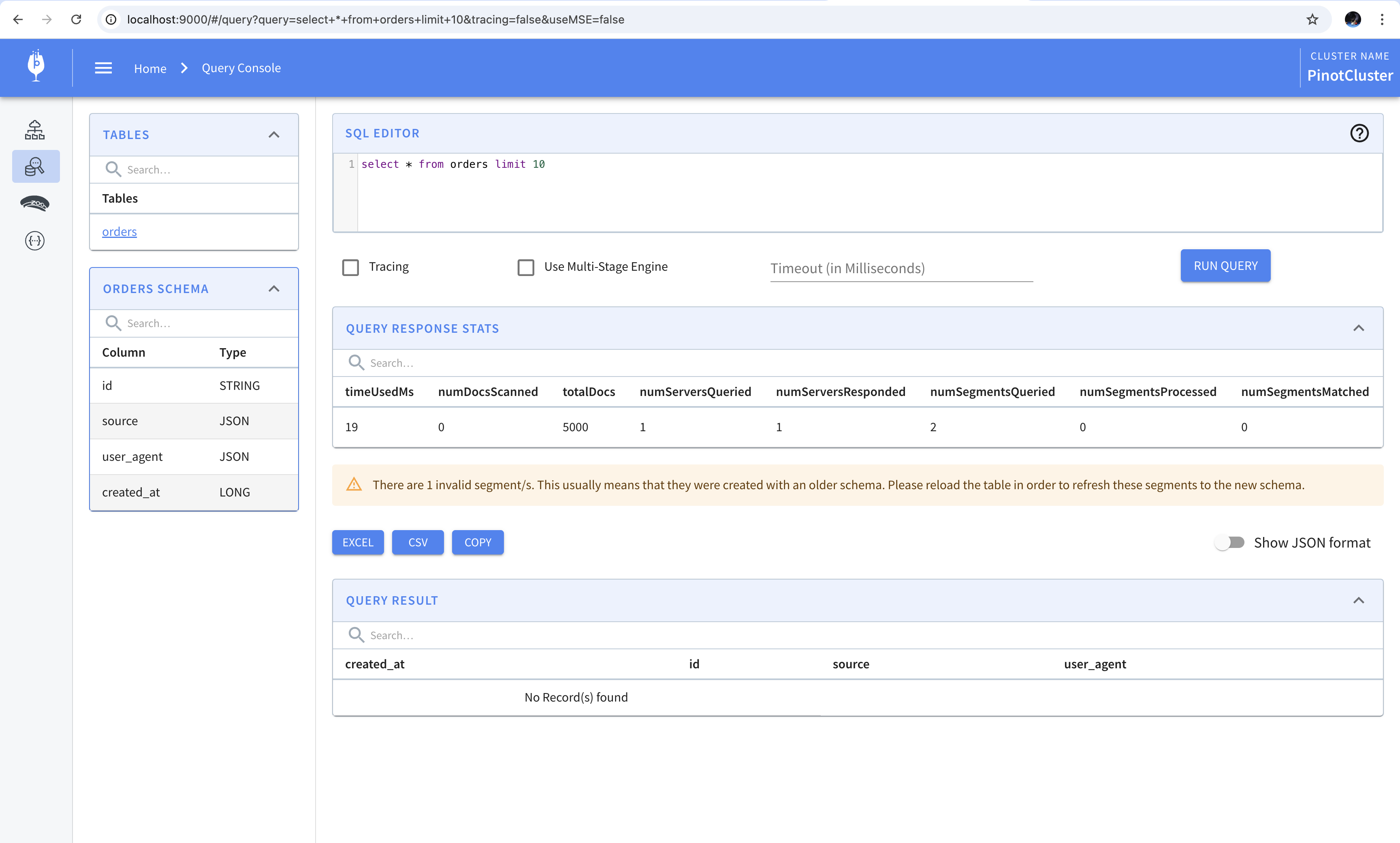
To update the table definition, we’ll add the following field-level transformation to the transformConfigs.
1 | { |
In this transformation we’re extracting the user_agent field into a column with the same name. Notice how we’re referencing the source column instead of the payload emitted by Debezium to get the value. Once we’ve made this change we’ll PUT the new table definition using curl.
1 | curl -XPUT -H 'Content-Type: application/json' -d @tables/002-orders/orders_table.json localhost:9000/tables/orders | jq . |
Finally, we’ll reload all the segments for this table using the following curl command.
1 | curl -XPOST localhost:9000/segments/orders/reload | jq . |
Upon opening the query console, we find that the a new user_agent column has been added to the table.
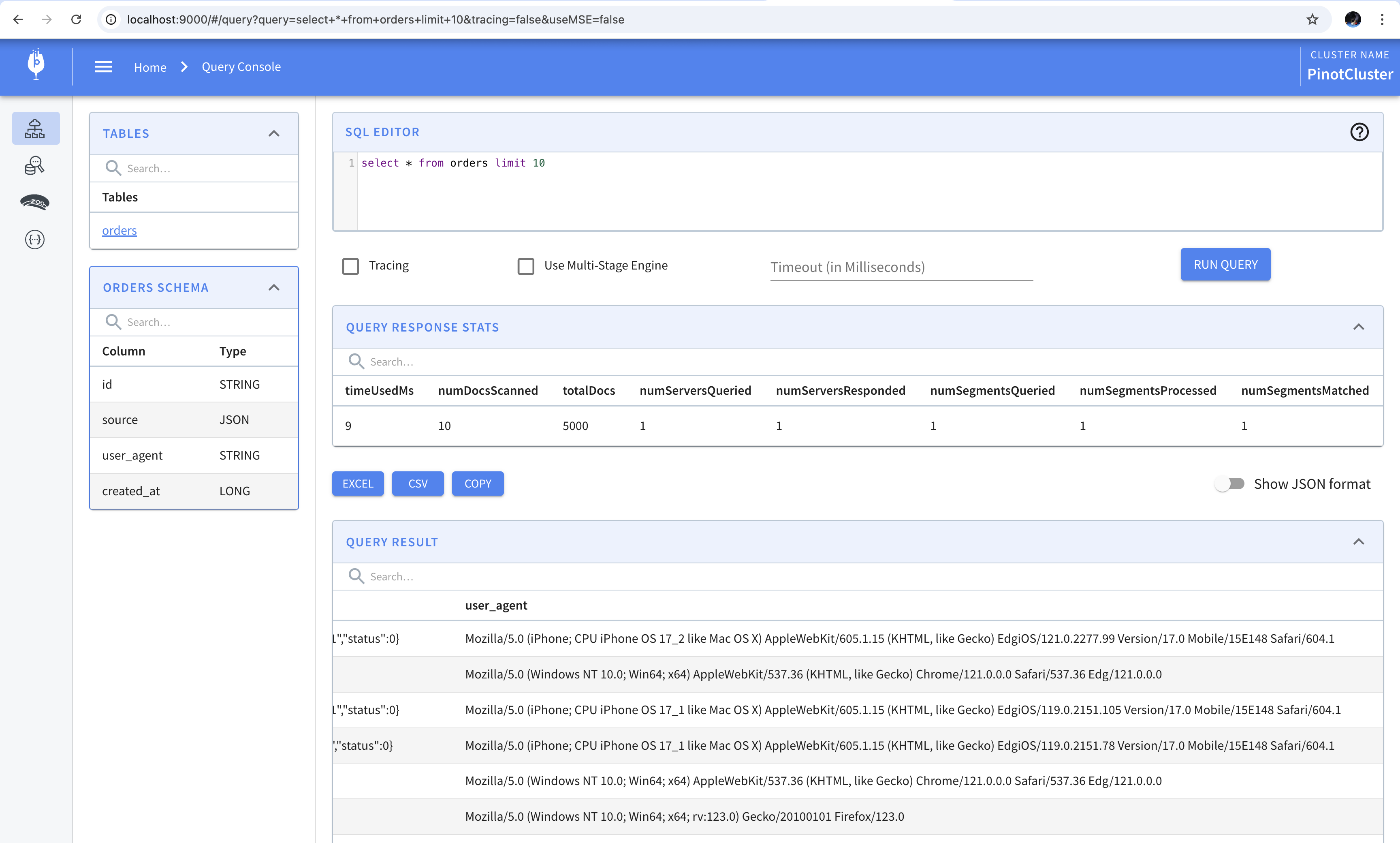
It’s common for the table to change with time as new columns are added. Consequently, the schema and table definitions will evolve in Pinot. As we update the schema in Pinot, we have to keep in mind that columns can only be added and not removed. In other words, the schema needs to remain backwards compatible. If you’d like to drop a column or rename it, you’ll have to recreate the table.
That’s it for how to evolve schema in Pinot.