I recently created an experimental library, detectpii, to detect PII data in relational databases. In this post we’ll take a look at the rationale behind the library and it’s architecture.
Rationale
A common requirement in many software systems is to store PII information. For example, a food ordering system may store the user’s name, address, phone number, and email. This information may also be replicated into the data warehouse. As a matter of good data governance, you may want to restrict access to such information. Many data warehouses allow applying a masking policy that makes it easier to redact such values. However, you’d have to specify which columns to apply this policy to. detectpii makes it easier to identify such tables and columns.
My journey into creating this library began by looking for open-source projects that would help identify such information. After some research, I did find a few projects that do this. The first project is piicatcher. It allows comparing the column names of tables against regular expressions that represent common PII column names like user_name. The second project is CommonRegex which allows comparing column values against regular expression patterns like emails, IP addresses, etc.
detectpii combines these two libraries to allow finding column names and values that may potentially contain PII. Out of the box, the library allows scanning column names and a subset of its values for potentially PII information.
Architecure
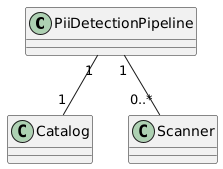
At the heart of the library is the PiiDetectionPipeline. A pipeline consists of a Catalog, which represents the database we’d like to scan, and a number of Scanners, which perform the actual scan. The library ships with two scanners - the MetadataScanner and the DataScanner. The first compares column names of the tables in the catalog against known patterns for the ones which store PII information. The second compares the value of each column of the table by retrieving a subset of the rows and comparing them against patterns for PII. The result of the scan is a list of column names that may potentially be PII.
The design of the library is extensible and more scanners can be added. For example, a scanner to use a proprietary machine learning algorithm instead of regular expression match.
Usage
To perform a scan, we create a pipeline and pass it a catalog and a list of scanners. To inititate the scan, we call the scan method on the pipeline to get back a list of PII columns.
1 | from detectpii.catalog import PostgresCatalog |
That’s it. That’s how to use the library to detect PII columns in tables.