I’d previously written about creating a realtime data warehouse with Apache Doris and Debezium. In this post we’ll see how to create a realtime data platform with Pinot, Trino, Airflow, Debezium, and Superset. In a nutshell, the idea is to bring together data from various sources into Pinot using Debezium, transform it using Airflow, use Trino for query federation, and use Superset to create reports.
Before We Begin
My setup consists of Docker containers for running Pinot, Airflow, Debezium, and Trino. Like in the post on creating a warehouse with Doris, we’ll create a person table in Postgres and replicate it into Kafka. We’ll then ingest it into Pinot using its integrated Kafka consumer. Once that’s done, we’ll use Airflow to transform the data to create a view that makes it easier to work with it. Finally, we can use Superset to create reports. The intent of this post is to create a complete data platform that makes it possible to derive insights from data with minimal latency. The overall architecture looks like the following.
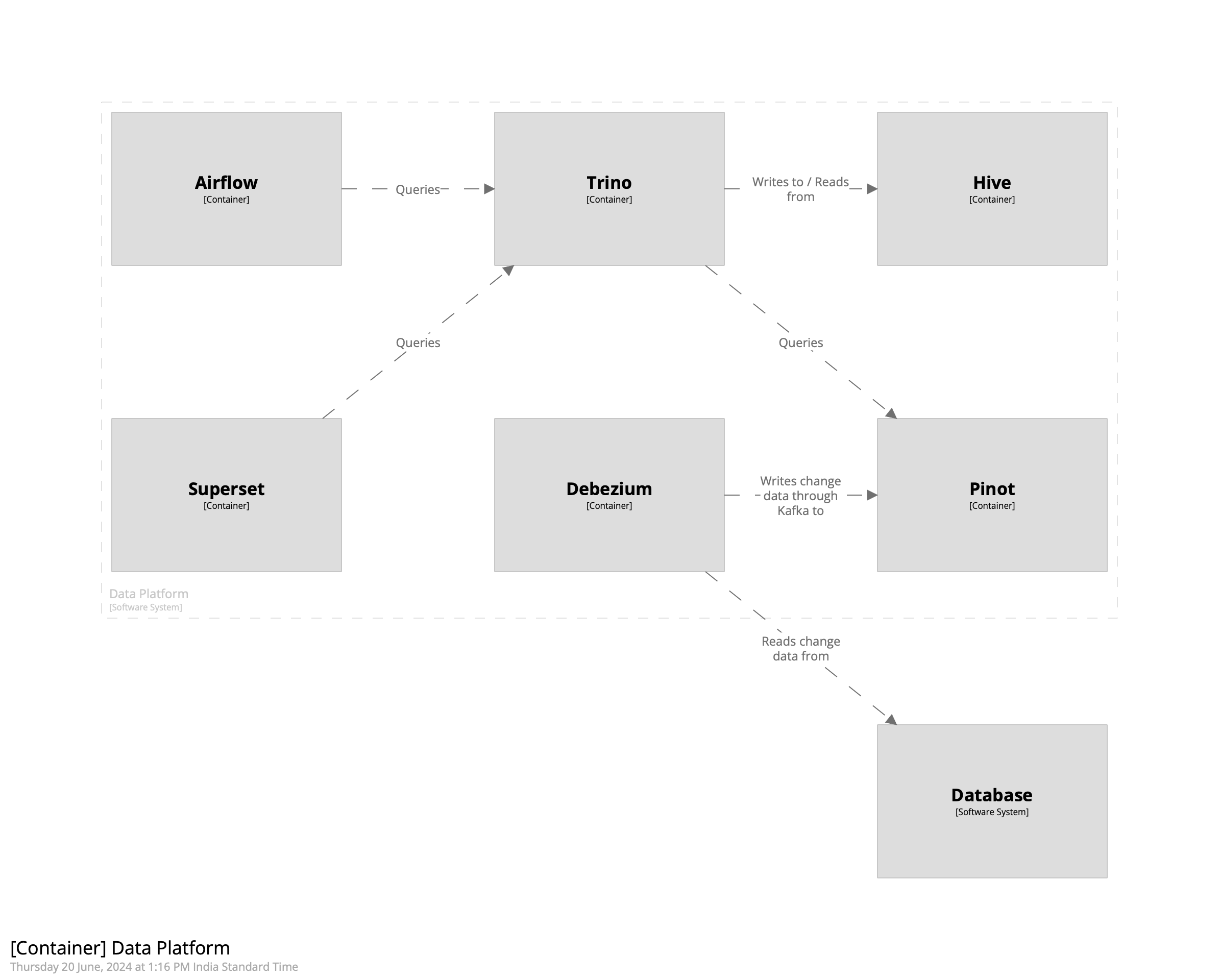
Getting Started
We’ll begin by creating a schema for the person table in Pinot. This will then be used to create a realtime table. Since we want to use Pinot’s upsert capability to maintain the latest record of each row, we’ll ensure that we define the primary key correctly in the schema. In the case of the person table, it is the combination of the id and the customer_id field. The schema looks as follows.
1 | { |
We’ll use the schema to create the realtime table in Pinot. Using ingestionConfig we’ll extract fields out of the Debezium payload and into the columns defined above. This is defined below.
1 | "ingestionConfig":{ |
Next we’ll create a table in Postgres to store the entries. The SQL query is given below.
1 | CREATE TABLE person ( |
Next we’ll create a Debezium source connector to stream change data into Kafka.
1 | { |
Finally, we’ll use curl to send these configs to their appropriate endpoints, beginning with Debezium.
1 | curl -H "Content-Type: application/json" -XPOST -d @debezium/person.json localhost:8083/connectors | jq . |
To create a table in Pinot we’ll first create the schema followed by the table. The curl command is given below.
1 | curl -F schemaName=@tables/001-person/person_schema.json localhost:9000/schemas | jq . |
The command to create the table is given below.
1 | curl -XPOST -H 'Content-Type: application/json' -d @tables/001-person/person_table.json localhost:9000/tables | jq . |
With these steps done, the change data from Debezium will be ingested into Pinot. We can view this using Pinot’s query console.
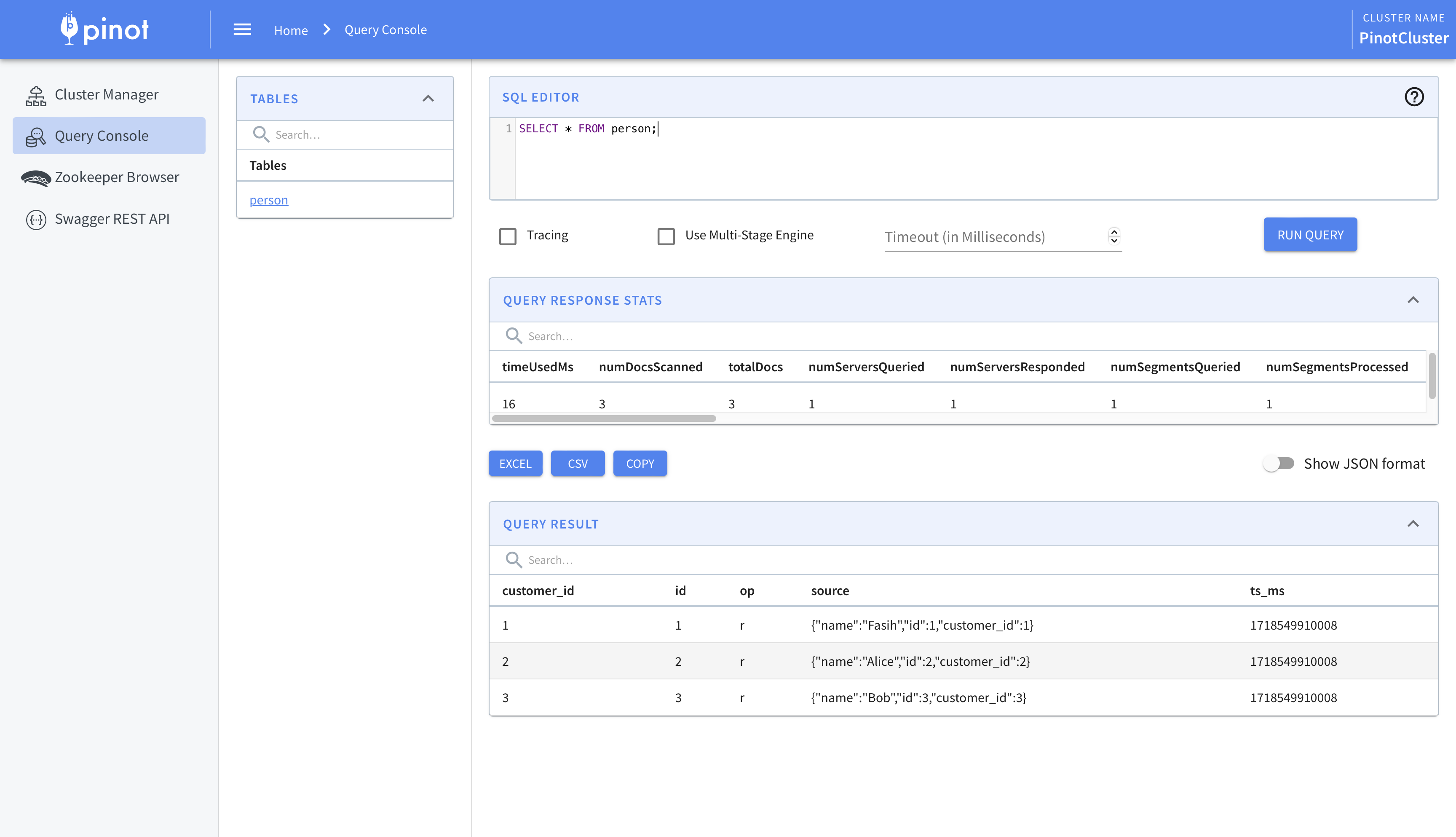
This is where we begin to integrate Airflow and Trino. While the data has been ingested into Pinot, we’ll use Trino for querying. There are two main reasons for this. One, this allows usto federate queries across multiple sources. Two, Pinot’s SQL capabilities are limited. For example, there is no support, as of writing, for creating views. To circumvent these we’ll create a Hive connector in Trino and use it to query Pinot.
The first step is to connect Trino and Pinot. We’ll do this using the Pinot connector.
1 | CREATE CATALOG pinot USING pinot |
Next we’ll create the Hive connector. This will allow us to create views, and more importantly materialized views which act as intermediate datasets or final reports, which can be queried by Superset. I’m using AWS Glue instead of Hive so you’ll have to change the configuration accordingly.
1 | CREATE CATALOG hive USING hive |
We’ll create a schema to store the views and point it to an S3 bucket.
1 | CREATE SCHEMA hive.views |
We can then create a view on top of the Pinot table using Hive.
1 | CREATE OR REPLACE VIEW hive.views.person AS |
Finally, we’ll query the view.
1 | trino> SELECT * FROM hive.views.person; |
While this helps us ingest and query the data, we’ll take this a step further and use Airflow to create the views instead. This allows us to create views which are time-constrained. For example, if we have an order table which contains all the orders placed by the customers, using Airflow allows to create views which are limited to, say, the last one year by adding a WHERE clause.
We’ll use the TrinoOperator that ships with Airflow and use it to create the view. To do this, we’ll create an sql folder under the dags folder and place our query there. We’ll then create the DAG and operator as follows.
1 | dag = DAG( |
Workflow
The kind of workflow this setup enables is the one where the data engineering team is responsible for ingesting the data into Pinot and creating the base views on top of it. The business intelligence / analytics engineering, and data science teams can then use Airflow to create datasets that they need. These can be created as materialized views to speed up reporting or training of machine learning models. Another advantage of this setup is that bringing in older data, say, of the last two years instead of one, is a matter of changing the query of the base view. This avoids complicated backfills and speeds things up significantly.
As an aside, it is possible to use DBT instead of TrinoOperator. It can be used in conjunction with TrinoOperator, too. However, I preferred using the in-built operator to keep the stack simpler.
Cost
Before we conclude, we’ll quickly go over how to keep the cost of the Pinot cluster low while using this setup. In the official documentation it says that data can be seperated by age; older data can be stored in HDDs while the newer data can be stored in SSDs. This allows lowering the cost of the cluster.
An alternative approach is to keep all the data in HDDs and load subsets into Hive for querying. This also allows changing the date range of the views by simply updating the queries. In essence, Pinot becomes the permanent storage for data while Trino and Hive become the intermediate query and storage layer.
That’s it. That’s how we can create a realtime data platform using Pinot, Trino, Debezium, and Airflow.