In the previous post we built the intuition behind linear regression. In this post we’ll dig deeper into the simplest form of linear regression which involves one dependant variable and one explanatory variable. Since we only have two variables involved, it’s called bivariate linear regression.
Ordinary Least Squares
We defined sample regression function as:
The term is called the residual. If we re-write the sample regression function, we get . The residual then represents how far off our estimated value is from the actual value .[1] A reasonable assumption to make is that we should pick and such that the sum of is the smallest. This would mean that our estimates are close to the actual values.
This assumption, however, does not work. Let’s assume that our values for are -10, 3, -3, 10. Here the sum is zero but we can see that the first and last predictions are far apart from the actual values. To mitigate this, we can add the squares of the residuals. We need to pick and such that the sum of the square of the residuals is the minimum i.e. is the least.
Again, assuming the values of to be -10, 3, -3, 10, the squares are 100, 9, 9, 100. This sums to 218. This shows us that the predicted values are far from the actual values. is called the residual sum of squares (RSS) or the squared error term.
The method of OLS provides us with estimators and such that, for a given sample set, is the least. These estimators are given by the formula:
where = , . These are the differences of individual values from their corresponding sample mean or . The estimators thus obtained are called least-squares estimators.
Now that we’ve covered significant ground, let’s solve a sum by hand.
Example
Let’s start by drawing a random sample from the original dataset. The sample I’ve drawn looks like this:
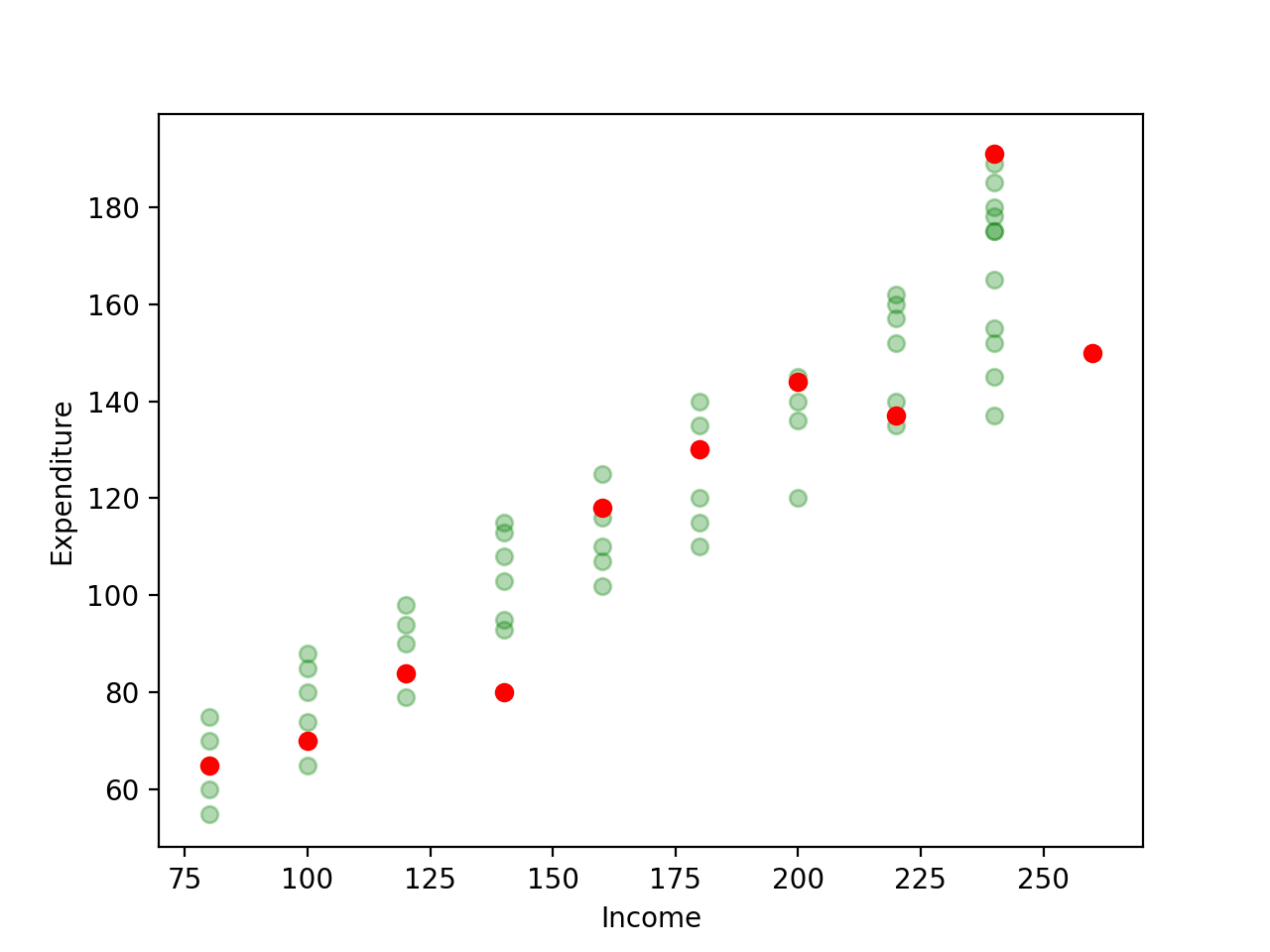
To see how this contrasts with the original dataset, here’s a plot of the original dataset and the random sample. The faint green points represent the original dataset whereas the red ones are the sample we’ve drawn. As always, our task is to use the sample dataset to come up with a regression line that’s as close as possible to the population dataset i.e. use the red dots to come up with a line that’d be similar to the line we’d get if we had all the faint green dots.
I’ll write some Python + Pandas code to come up with the intermediate calculations and the final and values. I highly recommend that you solve this by hand to get the feel for it.
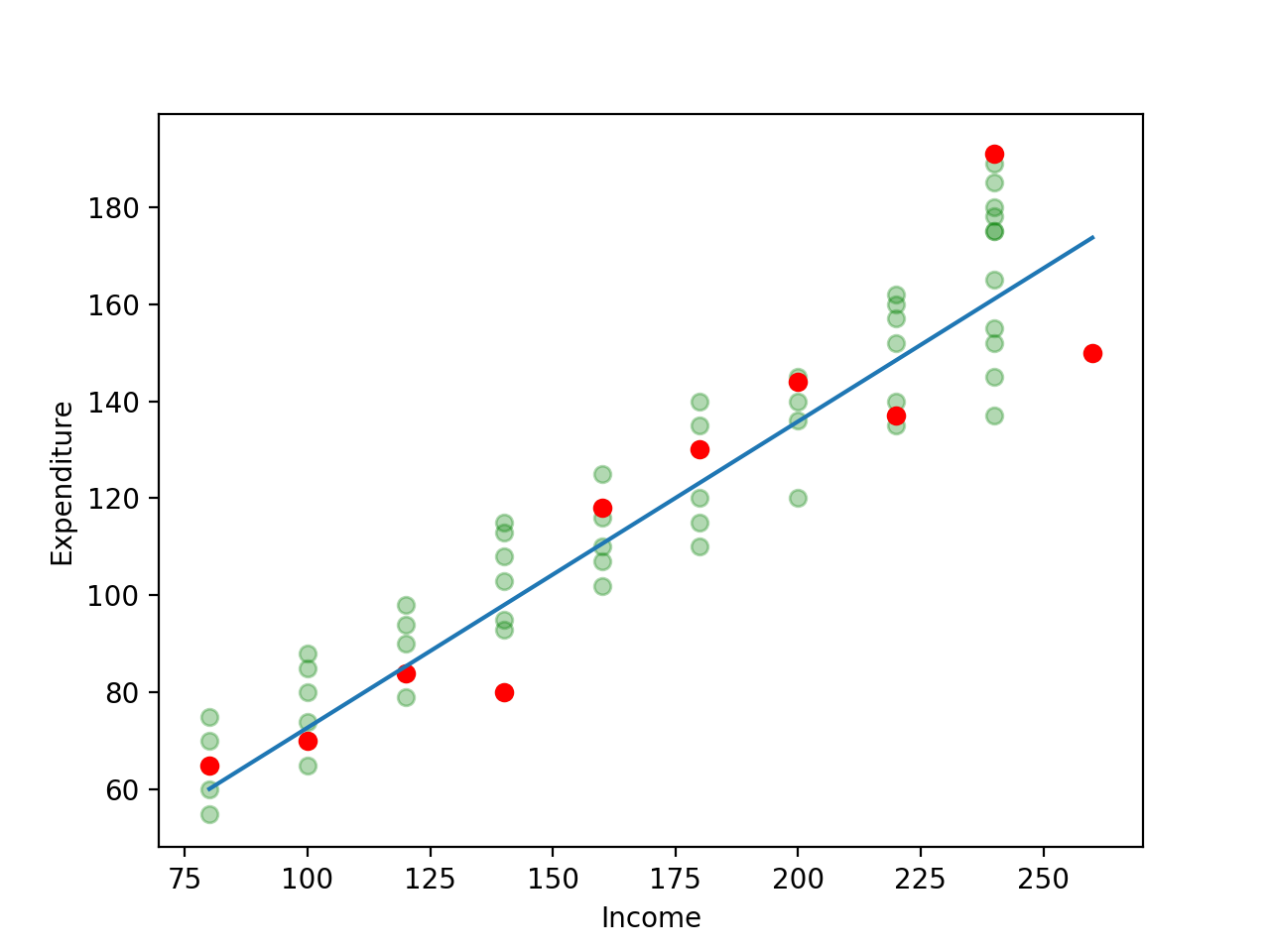
Let’s plot the line we obtained as a result of this.
Interpreting the Results
Our calculations gave us the results that and . Having a slope () of means that for every unit increase in income, there’s an increase of in expenditure. The intercept is where the regression line meets the Y axis. This means that even without any income, a persion would have an expenditure of . In a lot of cases, however, the intercept term doesn’t really matter as much as the slope and how to interpret the intercept depends upon what the Y axis represents.
Conclusion
That’s it for this post on bivariate linear regression. We saw how to calculate and and worked on a sample problem. We also saw how to interpret the result of the calculations. In the coming post we’ll look at how to assess whether the regression line is a good fit.
[1] It’s important to not confuse the stochastic error term with the residual . The stochastic error term represents the inherent variability of data whereas the residual represents the difference between the predicted and actual values of .