In the last two essays I mentioned the examples of Rambam, and Prophet Mohammed (pbuh), and how they pave the way for long-term peace. In this essay I’d like to introduce you to Rambam, and hopefully convey my admiration and reverence for him. While I originally wanted to title this essay as either “Revering Rambam” or “An Ode to Rambam”, I decided to call it “3rd essay” to make it a continuation of the previous two. In the same spirit, I shall handle this subject with sensitivity, and respect. If I inadvertently say something insensitive or disrespectful, I apologise from the beginning. The intention of this essay is to introduce you, the reader, to who I consider to be the most influential Judaeo-Arabic minds.
Let’s begin this essay with a thought experiment. I’d like you to close your eyes and imagine yourself standing in a park, or a cafe, or a meadow, or some place you consider beautiful. I’d like you to appreciate the beauty in its entirety, and then focus on the individual elements like the sights, the sounds, the smells, etc. that together make the scene beautiful. I posit that the beauty of Rambam’s thinking, like that of yours, is in the coalescence of individual elements. These are elements from his Jewish heritage, and those from his exposure to Islamic, and to some extent Christian, cultures.
Let us now look at Rambam’s life and works. I’ll start by attempting to piece together his life from whatever information I have. By the end of this essay, I hope to have conveyed what I suggested in the previous two, which is that Moshe and Moosa share a common thread of humanity through Rambam.
Moosa Ibn Maimoon al-Andalusi, also known as Moshe Ben Maimon ha-Sefaradi in Hebrew, known as Rambam, was born in the Arabic metropolis of Córdoba in 1135 or 1138. Descending from a long line of rabbanic scholars who preserved their genealogy, along with their titles, going back seven generations, he was one of two sons. He was quite fond of his younger brother, David, whom he educated and, as we will see later, trusted in affairs of business.[1]
Rambam was born towards the end of the golden age of Jewish culture in Spain, when the power of the governing dynasty of the Almovarids began to dwindle. They had granted Jews and Christians the dhimmi status. When we return to the Constitution of Medina, which Prophet Mohammed (pbuh) dictated, it states that any Muslim, even the weakest, is permitted to provide protection (dhimmah) to another person, and that it is binding on the rest of the Muslim Ummah. While the Constitution intends for it to be binding on Muslims living in Medina at the time, we can extrapolate that if the ruler of a nation grants dhimmi status to a group of people then it becomes binding on his subjects.
The Almohads rose to power, signaling the end of the golden age. Chroniclers describe the challenges of life as a Jew during the Almohad conquest, as well as persecution, when Abd al-Mu’min, the Almohad ruler, launched his conquest of North Africa and Andalusia.[2] Rambam’s family was forced to leave Cordoba, and eventualy moved to Fez, and then to Fustat.[3] During this period, Rambam was studying medicine, astronomy, rabbinic literature, and serving as an apprentice rabbinic judge.[4]
Rambam engaged in the precious stone trade in Fustat until the death of his brother David, who died in the Indian Ocean while doing business.[5] The Maimonides family had entrusted David with their savings in the hopes of growing their wealth. Rambam was deeply affected by his brother’s death, and in a letter found in the Cairo Geniza, a collection of Jewish manuscripts discovered in a storehouse (gheniza) of a synagogue in Fustat, Rambam laments how a tremendous sorrow had befallen him.[6]
The death of David led to financial hardship for the family of Rambam who had to take up the profession of the court-physician. Fustat, by now, was under the Ayyubid dynasty.[7] He confirms that he had studied both the theory and practice of medicine, and perhaps may have been preparing himself to become a physician. He did eventually gain renown for his profession, and even remarked that his attendance as a physician on Salah ad Deen’s courtesans was a fortunate turn in his life.[8] He even attendeed Salah ad Deen himself[9] and continued as a court-physician after his death.
He continued as a physician and passed away in 1204 in Fustat. His final resting place is in the city of Tiberias in Israel, and is one of the most important sites of pilgrimage.[10]
Take a moment to pause and reflect on the life of Rambam as that of, first and foremost, someone following the Jewish faith, and an intellectual living in the Mediterranean world. For a historian, however, the term “Mediterranean world” is problematic because the cultural boundaries are flexible; they can go from Italy in the West to Palestine in the East.[11] However, we can say that the Mediterranean world of the Islamic middle ages was one of economic relationships, exchange of books, science, and ideas, all of which contributed to the multifaceted universe in which Rambam lived.[12] We’ll take a quick look at only two of his sayings to demonstrate the brilliance of his ideas, beginning with another thought experiment; offering an overview of his work is beyond the scope of this essay.
The first saying, the thought experiment, serves as a guide for how we can think about Moshe and Moosa. In his book Dalalat al-Ha’irin, The Guide for the Perplexed, he states that when the process of thought is interrupted, “at first thought” (bi-awwal fikra), it is prone to create ideas that are incorrect, incomplete, or even dangerous.[13] Pause for a moment and reflect on your thoughts regarding Moshe and Moosa. I believe that, as Rambam stated, your first thought (fikra) was to see the other, depending on whose side you are on, in the most negative light. In the spirit of what has been mentioned in the Guide, we can take a minute to pause, reflect, and let the initial thought fade away to make place for the next.
Finally, I’d like to quote him from Commentary on the Mishnah. In that he writes that one should listen to the truth regardless of who says it; Isma’ al-haqq mi-man qalahu.[14] This is similar in structure to the advise of Ibn ‘Abbas, the cousin of Prophet Mohammed (pbuh) who said that one should take wisdom wherever it comes from, even if it comes from the non-wise. It is possible Rambam may have read this in Kindi’s Al Qutayba[15] since Jewish philosophers at his time read the work of their Muslim contemporaries. What matters less is whether he read it in the book, or if the idea was commonplace. What matters truly is the principle of reaching for knowledge and truth, whatever the source may be; this is the thread that ties Rambam with ‘Ibn Abbas.
This is me as I continue to look for peace in the land of the prophets.
Footnotes and References
[1] Page 4, Davidson HA. Moses Maimonides: The Man and His Works. Oxford University Press, USA; 2010. [2] Page 11, Davidson HA. Moses Maimonides: The Man and His Works. Oxford University Press, USA; 2010. [3] Page 8, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [4] Page 20, Davidson HA. Moses Maimonides: The Man and His Works. Oxford University Press, USA; 2010. [5] Page 9, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [6] Wikipedia contributors. Maimonides - Wikipedia [Internet]. 2024. Available from: https://en.wikipedia.org/wiki/Maimonides [7] Page 9, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [8] Page 35, Davidson HA. Moses Maimonides: The Man and His Works. Oxford University Press, USA; 2010. [9] Page 36, Davidson HA. Moses Maimonides: The Man and His Works. Oxford University Press, USA; 2010. [10] Wikipedia contributors. Tomb of Maimonides [Internet]. Wikipedia. 2024. Available from: https://en.wikipedia.org/wiki/Tomb_of_Maimonides [11] Page 9, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [12] Page 5, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [13] Preface, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [14] Page 11, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011. [15] Page 12, Stroumsa S. Maimonides in his world: Portrait of a Mediterranean Thinker. Princeton University Press; 2011.
I’d shared the first essay with my close friends in hopes of receiving feedback. I heard back from one of them saying that perhaps my essay, although hopeful, came a few years too late, and that it would be difficult to explain my stance to the people on either side, given everything that has transpired in the last few decades. This second essay is in defense of the first, and I shall try to explain why peace is still the way forward. As always, I shall handle this topic with utmost sensitivity, and I apologise if I inadvertently say things that come across as insensitive.
Let’s recap the first essay. We saw Moshe and Moosa, two 15 year old kids on either side of the conflict, who grow up to find themselves facing each other to defend what they consider to be their home. We then looked at the examples of Rambam, and Prophet Mohammed (pbuh) to see what the path to peace would look like. The story of Moshe, and Moosa remained incomplete. Like in the first essay, we will wind the clock forward a decade and look at the various ways in which things can unfold. Finally, we will posit that peace is still the only option.
Take a moment to reflect on your position on this issue. I hope that in the course of this essay I am able to allay any doubts you may have, and convince you to act towards making peace.
The first point that my friend had raised was that my essay is a few years too late. I’d like to address this by using the weiji (危机) metaphor that views a crisis as both a perilous situation, and a catalyst for change. It is the severity of the crisis that prompted me to write the essay, which will hopefully become the catalyst for lasting peace.
The second point that my friend had raised was that both the nations have tried to make peace in the past, and are yet to reach it. I’d like to respond by saying that the negotiations and treaties that were signed leave a lot to be desired. There is still lingering resentment and animosity on either side that shows from time to time. Also, the consequence of breaking down of the peace process is eternal war. Therefore, it stands to reason that attempts be made to ensure that it does not come to pass. It may, from the consciousnesses of the two nations, and of humanity, feel like rolling a boulder up the hill only to find it roll back down. To this I say that this is the only good pursuit there is.
The final point that my friend had raised was that perhaps Moshe would not want peace. This requires a more nuanced answer and we need to look beyond the consciousnesses of the two nations, and into the ones of those that surround them. We will look at these consciousnesses, and wind the clock forward a decade and reflect on the consequences of Moshe’s decisions. I’d like to retierate that I firmly believe in there being a common thread of humanity that ties Moshe and Moosa together, as we saw in the first essay, and that both Moshe and Moosa want peace and security for their homeland.
Let us now look at the theater of war.
Moshe’s nation, Israel, shares its border with 4 other nations. It has, at different points in time, been at war with its neighbors. All of them, however, share the consciousness of faith with Moosa. Further to the East is the nation where Moosa’s religion of Islam originated, and further to the West is another nation observant of the same faith. While Moshe’s nation, by itself, is militarily strong, and has powerful allies, there is a risk of conflict opening on multiple fronts.
In contrast, Moosa lives in Gaza, a small strip of land which is surrounded by Moshe’s nation on 2 sides, the sea on 1 side, and a neutral nation on 1 side which observes the same faith as he does.
Take a moment and reflect on the intricacies of the situation. In isolation, the war between Moshe and Moosa can be framed as a geopolitical dispute over borders. A borader look at the war reveals, given Moshe’s neighbors, that it can turn into a geo-religious-political dispute.
We’ll now look at two possible outcomes and wind the clock forward a decade to see how they may unfold. One, Moshe wins and manages to subdue Moosa, and his people militarily. Two, Moshe and Moosa end up in a stalemate. I posit that both of these outcomes are lose-lose for Moshe, and Moosa, and we shall see why.
Let us look at the first scenario where Moshe wins using military means, and manages to subdue Moosa and his nation. Such a victory is very myopic, and as counterintuitive as it may sound, goes against the original objective of securing his homeland. Given the collective consciousness of faith that Moosa’s nation shares with Moshe’s neighbors, near and far, there is now an ever-present threat of going to war with them, and perhaps simultaneously. It may happen either immediately, in the near future, in the far future, or never at all; the threat, however, shall remain. If it does happen, it risks drawing other nations of the world into it.
Also, military victory would come at a cost of significant civilian casualties to Moosa’s nation. While Moshe and his nation wins, they will forever be remembered, in the collective consciousness of humanity, as those who inflicted pain on those who had nothing to do with the war.
Those that do live through the war may now be left with no place to call home; Moshe did to Moosa’s people that which was done to his, and perhaps it will weigh heavily on him.
Take a moment and reflect on this outcome.
Let us now look at the second scenario where Moshe and Moosa end up in a stalemate.
In this scenario, neither Moshe nor Moosa win. After a long, drawn out war, Moshe and Moosa reach an agreement of sort that ends hostilities temporarily. In the course of the war, Moosa loses his wife and 2 daughters. I posit that such a scenario makes the next war even worse than the previous.
With time the military technology would advance, and with that the weapons of Moshe and Moosa. The nations that share the consciousness of faith with Moosa would do everything they can to help him, both militarily and diplomatically. Similarly, Moshe’s allies would help him militarily and diplomatically. Moshe would not have, still, achieved the objective of securing his homeland. Similar to the situation discussed previously, it has infact deteriorated the security of his nation. There is now a looming threat of Moosa retaliating with more fervor, and of drawing other nations into it.
Take a moment and reflect on this outcome.
I hope that this essay addresses any doubts as to why peace is the only way forward. The examples of Rambam, and Prophet Mohammed (pbuh) were deliberate as they tie Moshe and Moosa together. Let us envision a future where Moshe and Moosa sit across a table, say Salam Alaikum or Shalom Aleichem to the other, as children of Abraham and of humanity, heal the wounds that have been inflicted, bridge the divides that have been created, and bring their people a step closer to eternal peace. The road ahead is long, and paved with thorns, but what lies at the end is worth the walk.
This is me still looking for peace in the land of the prophets. Thank you for reading.
I recently read in a book that the Chinese word for crisis is weiji (危机). It consists of two characters: wei (危) meaning danger, and jei (机) meaning a point of inflection. In other words, a crisis is both a perilous circumstance and a catalyst for change. If handled correctly, a crisis can become an essential component and a powerful force for good. In this essay I am going to look at the Palestine and Israel crisis as weiji. I will draw on the collective consciousness of people on both sides to provide a stance that, I believe, will pave the way for long-term peace. This essay is my perspective, and I am only one of many people seeing the crisis unfold from a distance. I understand that this is a sensitive subject, and I will take every care to handle it as such. I am sure that I will inadvertently say things that people on both the sides will find insensitive, and for that I apologise from the beginning.
I’ll begin by introducing Moshe and Moosa, two young boys on either side of the conflict, and wind the clock forward a couple of times, one decade at a time, to show how they develop their consciousnesses. However, I’d like you to start by reflecting on your own position on the Palestine and Israel crisis, and hopefully watch it transform as we progress through the essay.
Let me introduce Moshe. He is 15 years old, and lives in the beautiful city of Tel Aviv. Like many kids his age living in the modern state of Israel, Tel Aviv is the only home he has known. He dreams of growing up and going to the university to follow in the footsteps of Jonas Salk. He is aware of the ever-present state of tension, and has heard the sirens go off as rockets land in his home city. In his history class he has studied about the Holocaust, the migration of the Jewish people in search of a home, and how that led to the formation of the modern state of Israel. He has also heard about the destruction of the Temple of Solomon from his rabbi. His consciousness as a young 15 year old kid is that of hopes and dreams, and his consciousness as an Israeli Jew is that of persecution, expulsion, and the search for a place to call home.
Let me now introduce Moosa. He, too, is 15 years old and lives in the beseiged city of Gaza. Like many kids his age living in under siege, Gaza is the only home he has known. He dreams of growing up and going to the university to become a surgeon after having seen the effects of shrapnel. He, too, is aware of the ever-present state of tension, and vividly remembers fighter jets and exploding bombs. He studies in a dilapidated school, and in his history class he has studied the formation of the modern state of Israel. He has heard the stories of the Naqbah from his grandfather, who wears the key to their old house around his neck. He yearns to go back and see the house his grandfather grew up in. His consciousness, as a young 15 year old kid, is that of hopes and dreams, and his consciousness as a Palestinian Muslim / Christian is that of persecution, expulsion, and of yearning to go back to the land his family once called home, and perhaps to play among the olive trees.
Take a moment to pause and reflect on the original position you started with. We shall now wind the clock forward a decade to a time where both Moshe and Moosa are 25 years old.
Moshe studied [1] medicine at the prestigious Tel Aviv University. He runs a successful practice, and is married to the love of his life that he met at the university. In the last 10 years, however, his country has come under attack twice. He now worries that, in the future, his children may not have a place to call home. He plans to run for political office with the hope of influencing policies and ensuring the security of Israel. His consciousness is that of someone looking out for his people; this is afterall his homeland.
Moosa got married to the girl who lives two houses from where he lives; they went to school together. He, too, is a doctor and runs a medical practice. In the last 10 years his city has twice witnessed a blockade, once for 90 days at a stretch. During this period there was only a trickle of food, and medical supplies; he had to scrounge for syringes, bandages, and medicines. He is among the many people who have lived through the blockade, including many young children. He has seen kids develop symptoms of post traumatic stress, and worries that the same will befall his children in the future. He plans to join the local political movement in hopes of bringing international pressure on the state of Israel. His consciousness is that of someone looking out for his people; this is afterall the only place left to call home.
Take a moment to pause and reflect on the original position you started with. We shall now wind the clock forward a decade to a time where both Moshe and Moosa are 35 years old.
Both Moshe and Moosa ran for political office, and now hold the highest position there is. While Moshe turns West to look for allies, Moosa turns East. They both use diplomatic, and military means to secure the place they call home. Their consciousnesses are of their nations, etched indelibly with the events of the last two decades. Nations of the world watch as the days unfold, and take the side of either Moshe or Moosa. People on each side portray the other in the most negative light.
Take a moment to pause and reflect on the original position you started with.
We begin to see the inflection point when we look at the crisis from the perspective of collective consciousnesses; there is a common thread of humanity that connects both Moshe and Moosa. To make this clear, I’d like to introduce one more Moshe or Moosa, someone I admire, and that is Moosa ibn Maimoon (Moshe, the son of Maimoon), also known as Rambam (רמב״ם) or more commonly as Maimonides. He was a prominent philosopher and polymath among both the Jewish and Islamic worlds.
Maimonides was born in either 1138 or 1135 in Andalusia[2]. During his early years, he studied Torah with his father and became interested in science and philosophy. He read Greek philosophers’ writings that were available in Arabic, as well as Islamic sciences and traditions. In 1148, however, after the Almohads conquered Cordoba, Maimonides’ family chose exile. He moved to Fez in Morocco, and eventually to Fustat in Egypt. He took up the profession of physician, for which he gained renown, and later became the physician of Salah ad Deen (Saladin). Among his notable achievements are treatises on medical and scientific studies, and the systematic codification of the Halakha, the way of life for the Jewish people.
Rambam’s life exemplifies a consciousness that offers peace to both Moshe and Moosa.
Take a moment to pause and reflect on the original position you started with.
While what is inscribed in Moshe and Moosa’s consciousnesses, as well as those of their nations and humanity, will endure, it is up to them to determine what will be etched in the future. I will now posit that the route to reconciliation stems from the life of Prophet Mohammed (pbuh), and provides a thread of humanity that can bind the consciousnesses of the two nations. His life, like that of Moshe, Moosa, and Rambam was the one of persecution, expulsion, and of finding a place to call home. He eventually found it in the city of Medina.
After migrating to Medina, Prophet Mohammed (pbuh) dictated what is called The Constitution of Medina.[3]. It mentions the rights and duties of the different tribes, Muslim and Jewish, and envisions a multi-religious Medina. While the complete text of the Constitution is left out for the sake of brevity, we shall look at two statements that truly capture the essence of this essay.
“They (Muslims) shall constitute a separate Ummah as distinguished from the people (of the world) … And the Jews of Banu ‘Awf shall be considered as one Ummah along with the believers — for the Jews their religion, and for the Muslims theirs, be one client or patron.”
The word the Constitution uses is Ummah which translates to a community. However, a closer look at the word reveals its profundity. Ummah dervies from Umm or Amm which means mother. Ummah is, therefore, people who are so close that they might have descended from the same mother. This is an apt description for the followers of the two Abrahamic faiths; one descends from Ishaq (Issac), and the other from Ismail (Ishmael). It is within the realm of reason to view the people of both the faiths coexisting side-by-side in harmony.
We can now reframe the Palestine and Israel conflict as the one where two Ummahs lay claim to the land of their common ancestor Abraham. This, in my opinion, is the most peaceful way to look at the crisis.
Let us now critique the essay by saying that the juxtaposition between Moshe and Moosa is wrong, and that the examples of Rambam and Prophet Mohammed (pbuh) are out of place. Perhaps this criticism is correct, and all we have is an amalgamation of random thoughts that have been weaved together. In it’s defense, we can say that the alternative is eternal tension, animosity, and war.
The path ahead, should the passage of time unfold itself to bring this essay into reality, is long and arduous. Whatever wrong, perceived or genuine, that has been to both the sides can only be partially undone. However, there is also hope of lasting peace and serenity in the intertwined consciousnesses of both Moshe and Moosa. The walls that they have built will take time to come down but it only takes a kind word, an extended hand, and a gracious smile to connect the two hearts.
This is me looking for peace in the land of the prophets. Thank you for reading.
Footnotes:
[1] I have but the faintest idea at what age people graduate medical school. [2] I am using Wikipedia as my source. Maimonides. [3] I am using Wikipedia again. The Constitution of Medina.
Let’s begin with some reflection. I’d like you to recall the last time you were in a public place, such as a café, a restaurant, or a crowded train station. What did you observe? Pause for a moment and consider it. In this essay, we’ll look at a perspective on the world that I believe will help you understand the intricacy of the interconnected world in which we live.
Imagine yourself as a dot on a piece of paper; this is who you are in the big picture. Your views, life experiences, and perceptions all shape who you are. They come together to build your consciousness. Let us now place a few additional dots around you to represent your family. Individuals in your family have separate consciousnesses, but because they share experiences, they now have a shared consciousness. Birthdays, graduations, births and deaths, and so on are all regular life events that everyone in the family will remember. This is the collective conscience of a family, or more broadly, a group of people. We shall continue to generalize until we have a collective consciousness of humanity.
Let us now draw a box around your family, followed by a few nearby boxes with dots. This represents the neighborhood. People in the neighborhood have similar experiences, which are determined by a variety of characteristics such as socioeconomic status, ethnicity, shared or conflicting values, and so on. Each neighborhood possesses its own consciousness. A village, town, or city is formed when many of these neighborhoods are combined together. When several such villages, towns, and cities are combined, they form a province, and when numerous provinces are combined, we have the modern nation with well-defined borders.
The nation’s collective consciousness is molded by past and present events, as well as its vision for the future. These events might be positive, such as major achievements, or negative, such as wars, famines, epidemics, acts of terror, and so on. The consciousness of many such nations together constitutes humanity’s collective consciousness, which extends back throughout time.
The framework we’ve looked at offers a highly humanistic perspective on individuals and humankind as a whole. We’ve looked at a pretty static picture of collective consciousness in which individuals are represented as dots, but in the next sections, we’ll look at a more dynamic view in which the dots move around to interact with other dots. Like in previous sections, we’ll begin with one dot, the individual, and work our way up to a collection of dots, the nation.
Assume that each dot is now colored according to its national flag and moves freely, interacting with other dots. The very first dots to come into contact are those within the family. As a dot moves further away, it may come in contact with dots from its own neighborhood, from another province, or from a different nation altogether. When a dot interacts with another dot, an exchange of ideas occurs. As a result, there will be dots with similar ideas and those with differing ideas; one will come across others who have similar beliefs. These ideas can be political, religious, economic, moral, or any other topic on which one has an opinion. In other words, dots with similar consciousness prefer to attract each other. Finally, a nation is a collection of many consciousnesses that function as one. However, spontaneous interaction among groups of dots with no organization produces friction and chaos. As a result, guiding principles must exist to determine how consciousnesses interact. These compose the nation’s constitution. We can now begin to conceive of a nation’s laws as principles influencing migrating consciousness, and are themselves created from the collective consciousness the nation. The interaction among nations, either for war or for trade, can be viewed as interactions among consciousnesses of that nation and just as laws govern interaction among individuals, they govern interaction among nations.
As a result, you, the reader, have your individual consciousness as well as a connection to the wider human consciousness. Your deeds and the life you build will be indelibly inscribed in the memory of time.
In critique of my own train of thought, I’d want to point out that the framework I provided is overly simplistic and fails to account for the endless variety of existence. For example, it does not discuss the life of an orphaned child. However, in its defense, the model may be expanded to explain it as well.
Thank you for reading my pseudo-philosophical post. I’d like to reiterate the question: what do you see when you stand in a crowded area?
My fiancee recently asked me why random things happen in life. For example, someone winning a lottery. The best answer I could come up with was that it is divine preordainment; we’re both religious. However, I’ve been thinking about a more mathematical approach to view life, and its randomness. In a nutshell, I view life as a set of random variables. This post is banter, so please take it as such.
Let’s view life as a set of discrete, and continuous random variables; . These infinite variables could represent multiple things. For example, median income, level of education, IQ, EQ, Haleema, etc. Any given person’s life is a collection of a subset of values of these variables. We could represent my life as . Let us now define a random process which can alter the set of values within ; values can be added, removed, or updated. As an example, the value of median income can be changed by .
We can now introduce a continuous variable (goal) which takes on values between and , inclusive. This is a measure of how close one is to achieving what they want in life. This can either be affected by a single random variable from , or it can be a composite score derived from multiple variables. Someone may view their life as the outcome of a single variable, or as a composite score derived from multiple variables. Everyone has a baseline value of that makes them feel fulfilled and happy; the more carefree may be okay with a lower value, where as the more careful may want a higher value. This is similar to risk tolerance when making financial decisions. There is the target value of which one would like to achieve; this means they’ve achieved their goal in life.
We’ll introduce one final variable (ability), and that is, as you may have guessed, a measure of person’s abilities. This takes on values between and , inclusive. It is a measure of a person’s ability to alter the value of given any random subset of variables. For example, a person with high value of may be able to maintain the baseline value of , or be able to move it towards the target value regardless of the values of the subset of .
This is the lens with which I view the world, and I hope you had a good time reading this post.
A common requirement for a data warehouse is to store data from third-party sources like SaaS tools. For example, results of surveys conducted by Product or Marketing teams, or status of JIRA tickets. While most of these tools provide an option to export data, it could be very limited. For example, they’d only allow downloading it as a CSV file from their dashboard as a one-off download. Some of them provide APIs to export data which is a lot more convenient. Of those that do provide a direct integration with a warehouse, it’d be with the commercial ones like Snowflake. If we’re using a different warehouse, it is going to take some engineering effort to periodically get this data.
In this post we’ll look at how we can streamline this ingestion. As always, we’ll use open-source technologies to do this. Like in my previous post, we’ll use Doris as our data warehouse. We’ll use the open-source tool Meltano to fetch data from a Github repository. While this is not going to fully replace the need to write custom code, it will help us benefit from the collection of open-source connectors that come with Meltano.
Setting things up
Like in my previous post, my setup consists of Docker containers for running Doris locally. There’s a Postgres container that runs as a part of this setup. We’ll install Meltano, and ingest data into a Postgres database. We’ll then create a catalog in Doris that points to the data ingested in Postgres. While it may be possible to ingest the data directly into Doris by letting Meltano write it to S3, I find it much easier to write it to a database.
Getting started
For the purpose of this post we’ll will be modifying the example on Meltano’s website to ingest data from Github to Postgres. Meltano is available as a pip package and I already have a Conda environment in which it is installed. I’ll gloss over the steps that show how to create a Meltano project for the sake of keeping the post brief, and jump right into the ones where we add the Github extractor, the Postgres loader, and configure them.
Let’s start by adding the loader, and the extractor plugins.
We’ll then configure them one-by-one, starting with the Github plugin. We’ll add the repository we’d like to fetch data from, and the auth token that will be used to authenticate with Github.
1 2
meltano config tap-github set repositories '["thescalaguy/blog"]' meltano config tap-github set auth_token '...'
Next we’ll configure the Postgres plugin. We’ll ingest the data into a schema called “github” in the “ingest” database.
1 2 3 4 5 6
meltano config target-postgres set user postgres meltano config target-postgres set password my-secret-pw meltano config target-postgres set database ingest meltano config target-postgres set port 6432 meltano config target-postgres set host 127.0.0.1 meltano config target-postgres set default_target_schema github
Finally, we run the pipeline.
1
meltano run tap-github target-postgres
A successful run of the pipeline will create a whole bunch of tables in Postgres. One such table is “repositories”, and we’ll query it next.
1
SELECT id, repo, org, name FROM repositories;
The query above gives us the following row.
1 2 3
| id | repo | org | name | |----------|------|-------------|------| | 95359149 | blog | thescalaguy | blog |
We’ll now create a catalog in Doris that points to the database in Postgres. To do this we need to execute the CREATE CATALOG command. Notice that we’ve specified the driver_url that points to Maven. This is a lot easier than manually downloading the JAR, and making it available in the Docker container.
We have one last step before we can query the data, and that is to fix a few symlinks in the containers. It looks like the code is looking for CA certificates at a location different than where they actually are. From what I could glean from the documentation, perhaps the base image has changed and the paths need to be upadted. In any case, here’s how to fix it both in the FE and BE containers by docker exec-ing into them.
Now we’ll run a SELECT query. Notice how we’re writing the FROM clause; it is catalog.schema.table.
1 2
SELECT id, repo, org, name FROM meltano.github.repositories;
There are, however, limitations to what we can read from the Postgres table. Some of the column types are not supported. Changing the query to SELECT * will raise an error that “topics” column is not supported. We can describe the table in the catalog to check which of the columns cannot be read.
1
DESC meltano.github.repositories;
The result shows “UNSUPPORTED_TYPE” next to “topics” column. This is perhaps because Doris uses MySQL protocol and there’s no equivalent mapping bewteen Postgres and MySQL for that type. One way to mitigate this is to create a new column using Meltano’s stream_maps, and parse it in Doris.
That’s it. That’s how we can ingest data from third-party systems into Doris.
I have a few requirements when choosing a SQL IDE. I’d like to use something that is relatively modern, has good support for a wide variety of databases, and allows making charts and graphs. I looked at Metabase, TablePlus, DBeaver, DataGrip, and Apache Superset. All of these tools have a feature or two that is missing in the other. For example, DataGrip allows creating entity relationship diagrams that make it easy to understand how the tables are related to each other; many of the tools do not have this feature. The free version of TablePlus allows creating only one set of charts; Metabase and Superset allow creating many of these. For my day-to-day requirements, as you may have guessed from the title of this post, Apache Superset is the best fit. This post shows how to quickly set up Superset using Docker Compose.
Why Superset
One of the things I often need to do is to monitor the performance of a system. For example, building upon the previous post where I talked about a hypothetical notification delivery system, counting how many notifications are being sent out per day, both as an aggregate metric across channels, and per-channel. This can be tracked by generating StatsD metrics, and charting them in Grafana. However, chances are that we’d need to display them to the customer, and also to other non-technical stakeholders. To do this we’d need our systems to generate records in the database, and have these be stored in a data warehouse that we can eventually query. This is where Superset is useful; it has built-in IDE that allows exploratory data analysis, and the ability to create charts once we’ve finalised the SQL query. The query can then be made part of the application serving analytics, or the BI tool that is used to by the stakeholders.
Another reason is that it is an open-source, actively-developed project. This means bug fixes and improvements will be shipped at a decent cadence; we have a tool that will stay modern as long as we keep updating the local setup.
Finally, because it is an open-source project, it has good documentation, and a helpful community. Both of these make using a technology a pleasant experience.
Setting up Superset
Superset supports a wide vartiety of databases. However, we need to install drivers within the Docker containers to support additional databases. For the sake of this example, we’ll install the Snowflake driver. To set up Superset locally we need to clone the git repo. Let’s start by doing that.
1
git clone https://github.com/apache/superset.git
Next we navigate to the repo and add the Snowflake driver.
1 2 3
cd superset echo"snowflake-sqlalchemy" >> ./docker/requirements-local.txt echo"cryptography==39.0.1" >> ./docker/requirements-local.txt
I had to add the cryptography package manually because the first time I set up Superset, logs showed that database migrations did not run becasuse it was missing.
Next we checkout the latest stable version of the repo. As of writing, it is 3.0.1.
1
git checkout 3.0.1
Now we bring up the containers.
1
TAG=3.0.1 docker-compose -f docker-compose-non-dev.yml up -d
This will start all the containers we need for version 3.0.1 of Superset. Note that if we add newer drivers, we’ll need to rebuild the images. Navigate to the Superset login page and use admin as both the username and password. We can now follow the documentation on how to set up a data source, and use the SQL IDE to write queries.
One of the GoF design patterns is the facade. It lets us create a simple interface that hides the underlying complexity. For example, we can have a facade which lets the client book meetings on various calendars like Google, Outlook, Calendly, etc. The client specifies details about the meeting such as the title, description, etc. along with which calendar to use. The facade then executes appropriate logic to book the meeting, without the client having to deal with the low-level details.
This post talks about how we can create a facade in Python. We’ll first take a look at singledispatch to see how we can call different functions depending on the type of the argument. We’ll then build upon this to create a function which dispatches based on the value instead of the type. We’ll use the example given above to create a function which dispatches to the right function based on what calendar the client would like to use.
Single Dispatch
The official documentation defines single dispatch to be a function where the implementation is chosen based on the type of a single argument. This means we can have one function which handles integers, another which handles strings, and so on. Such functions are created using the singledispatch decorator from the functools package. Here’s a trivial example which prints the type of the argument handled by the function.
@echo.register defecho_int(x: int): print(f"{x} is an int")
@echo.register defecho_str(x: str): print(f"{x} is a str")
if __name__ == "__main__": echo(5) echo("5")
We start by decorating the echo function with singledispatch. This is the function we will pass our arguments to. We then create echo_int, and echo_str which are different implementation that will handle the various types of arguments. These are registered using the echo.register decorator.
When we run the example, we get the following output. As expected, the function to execute is chosen based on the type of the argument. Calling the function with a type which is not handled results in a noop as we’ve set the body of echo to ellipses.
1 2
5 is an int 5 is a str
When looking at the source code of singledispatch, we find that it maintains a dictionary which maps the type of the argument to its corresponding function. In the following sections, we’ll look at how we can dispatch based on the value of the argument.
Example
Let’s say we’re writing a library that lets the users book meetings on a calendar of their choosing. We expose a book_meeting function. The argument to this function is an instance of the Meeting data class which contains information about the meeting, and the calendar on which it should be booked.
Code
Model
We’ll start by adding an enum which represents the calendars that we support.
1 2 3 4 5 6
import enum
classCalendar(str, enum.Enum): GOOGLE = "google" OUTLOOK = "outlook"
Next we’ll add the data class which represents the meeting as a dataclass.
Finally, we’ll start creating the facade by adding functions which will dispatch based on the value of calendar contained within the instance of Meeting.
Dispatch
We’ll create a registry which maps the enum to its corresponding function. The function takes as input a Meeting object and returns a boolean indicating whether the meeting was successfully booked or not.
Next we’ll add the book_meeting function. This is where we dispatch to the appropriate function depending on the meeting object that is received as the argument.
1 2 3 4 5 6 7
defbook_meeting(meeting: Meeting) -> bool: func = registry.get(meeting.calendar) ifnot func: raise Exception(f"No function registered for calendar {meeting.calendar}") return func(meeting)
To be able to register functions which contains the logic for a particular calendar, we’ll create a decorator called register.
1 2 3 4 5 6 7
defregister(calendar: Calendar): def_(func: MeetingT): if registry.get(calendar): raise Exception(f"A function has already been registered for {calendar}") registry[calendar] = func return func return _
register accepts as argument the calendar for which we’re registering a function. It returns another higher-order function which puts the actual function in the registry. Since the actual logic of the execution is in the decorated function, we simply return the original function func.
Finally, we register functions for different calendars.
1 2 3 4 5 6 7 8 9 10
@register(Calendar.GOOGLE) defbook_google(meeting: Meeting) -> bool: print(f"Booked Google meeting") returnTrue
@register(Calendar.OUTLOOK) defbook_outlook(meeting: Meeting) -> bool: print(f"Booked Outlook meeting") returnTrue
We’ll put all of this code in action by trying to book a meeting on Google calendar.
This prints “Booked Google meeting”, like we’d expect. We can now continue to add more functions which contain logic for specific calendars. Our library can evolve without any change to the exposed interface. It’s also possible to organise functions into their own modules, import the register decorator, and decorate them to add them to the registry. This has two main benefits. One, we keep the code well structured. Two, the code for different versions of the same calendar can stay separated; we avoid having to write if checks to see the calendar version since that can be made part of the enum itself, like GOOGLE_V1.
That’s it. That’s how you can create a facade in Python.
Let’s start with an exercise: ask two of your colleagues to create an architecture for a moderately-complex CRUD app. Chances are that they’d look very different from each other. They’d look different because the notations used to depict different parts of the system, like a database, for example, are different. Additionally, everyone has a favorite tool like DrawIO, LucidChart, paper towel, etc. for drawing these diagrams. This approach only works well for rapid prototyping. The drag-and-drop nature of most drawing tools, and paper towel’s susceptibility to getting lost make documenting large software systems a less-than-pleasant experience.
This post describes how to use code to create software architecture diagrams and then commit them to version control. We’ll look at the process and tools for producing consistent diagrams at various abstraction levels, ranging from high-level to low-level. To achieve this, we will create a fictitious notification delivery system. After reading this you should be able to draw diagrams for your own systems at various levels of detail, and be able to explain them to different types of audiences.
In the first part we will talk about why it is necessary to represent the system at various levels of abstraction. In the second part we will talk about notations we can use to draw our system. In the last part we will work through the notification delivery system and create different types of diagrams for it. If you’re looking for an introduction-by-example, feel free to skip to the third part.
Abstraction
Consider a typical software engineering team. You can categorize the people in the team as “engineers” or “not engineers”. Product managers and other stakeholders would make up the “not engineers” portion of the team. They require a broad overview of the system. Within the engineering team, too, people look at the system at different levels of detail. A junior engineer, for example, would focus on the subsystem they are working on while passing by the other subsystems. A more senior engineer, on the other hand, would be expected to be intimately familiar with many systems. This requires presenting the system at different levels of abstraction, depending on the intended audience.
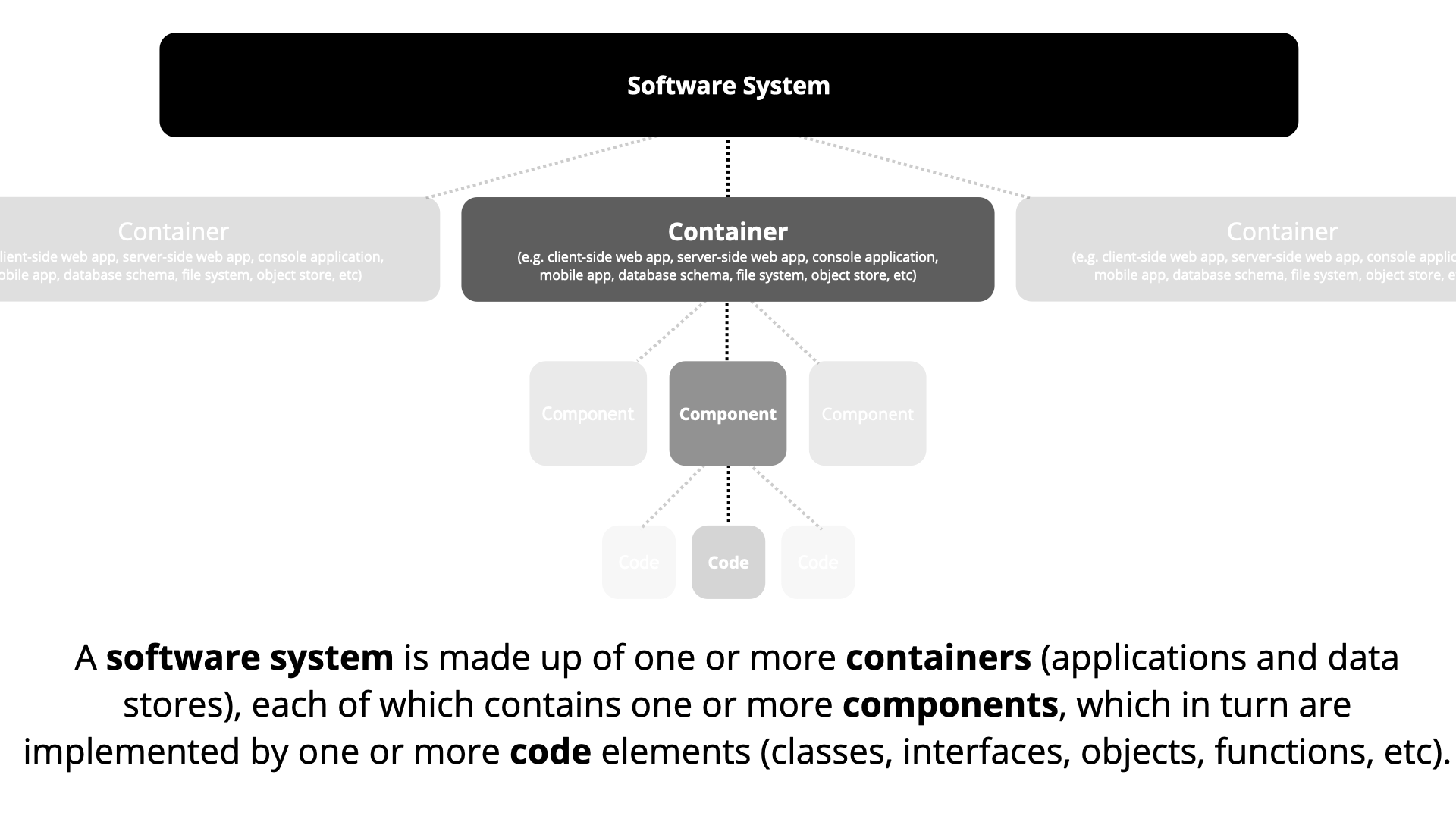
The C4 model allows us to create such views of the system - from the least to the most detailed. The four C’s of the model stand for context, containers, components, and code. A system is made up of many containers (applications, databases, etc), each of which contains multiple components (various API controllers, etc), which are made up of code elements (individual classes, functions, interfaces, etc.). The diagram below, taken from C4 model’s website, shows how they are arranged in a hierarchy.
Given the hierarchy of the four C’s, we can create diagrams at different levels of abstraction. For example, a high-level diagram which only shows different software systems. The highest-level diagram is called the system landscape diagram. This shows how our system fits into the larger scheme of things. The system context diagram narrows the focus by showing our system and the systems that it interacts with. A container diagram adds more detail by showing the responsibilities of different subsystems that together make up our system. Finally, a code diagram shows the most detailed view consisting of class hierarchies, ER diagrams, etc.
Creating such diagrams is helpful because it lets us communicate effectively. For example, we’d use the system landscape or system context diagram when discussing the scope of changes with the product team. A junior engineer, on the other hand, could work their way through the different types of diagrams to get a sense of how the system works.
Writing code to generate these multiple perspectives of the system is a really convenient method, as you’ll see later in the post. All of the views can be generated automatically by the same code. In comparison, you could use a drag-and-drop tool. However, keeping all the diagrams in sync with each other gets tiresome and error-prone.
Notation
Languages like UML are very heavy on notation. For example, the notation to draw a component diagram is very different from a sequence diagram. In contrast, the C4 model is very light on notation. As a starting point, you could represent different diagrams using boxes and arrows, and then augment them with shapes and colors to convey more information. This makes it easy for different people to understand the diagrams without getting bogged down in notation.
As you’ll see in the example that follows, we’ll start with boxes and arrows. For example, the database would be represented as a grey box. We’ll then change it’s shape and color to make it a blue cylinder.
Example
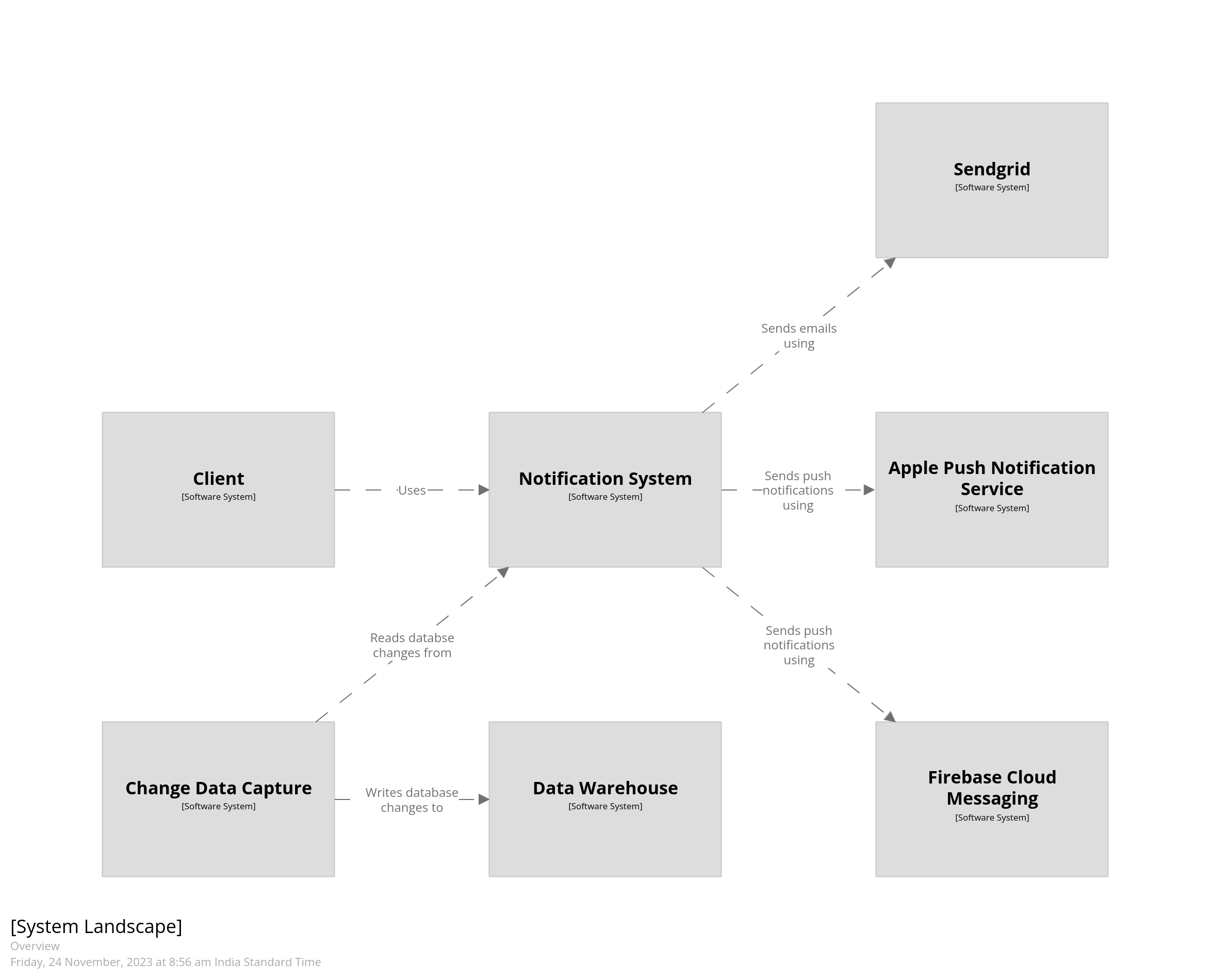
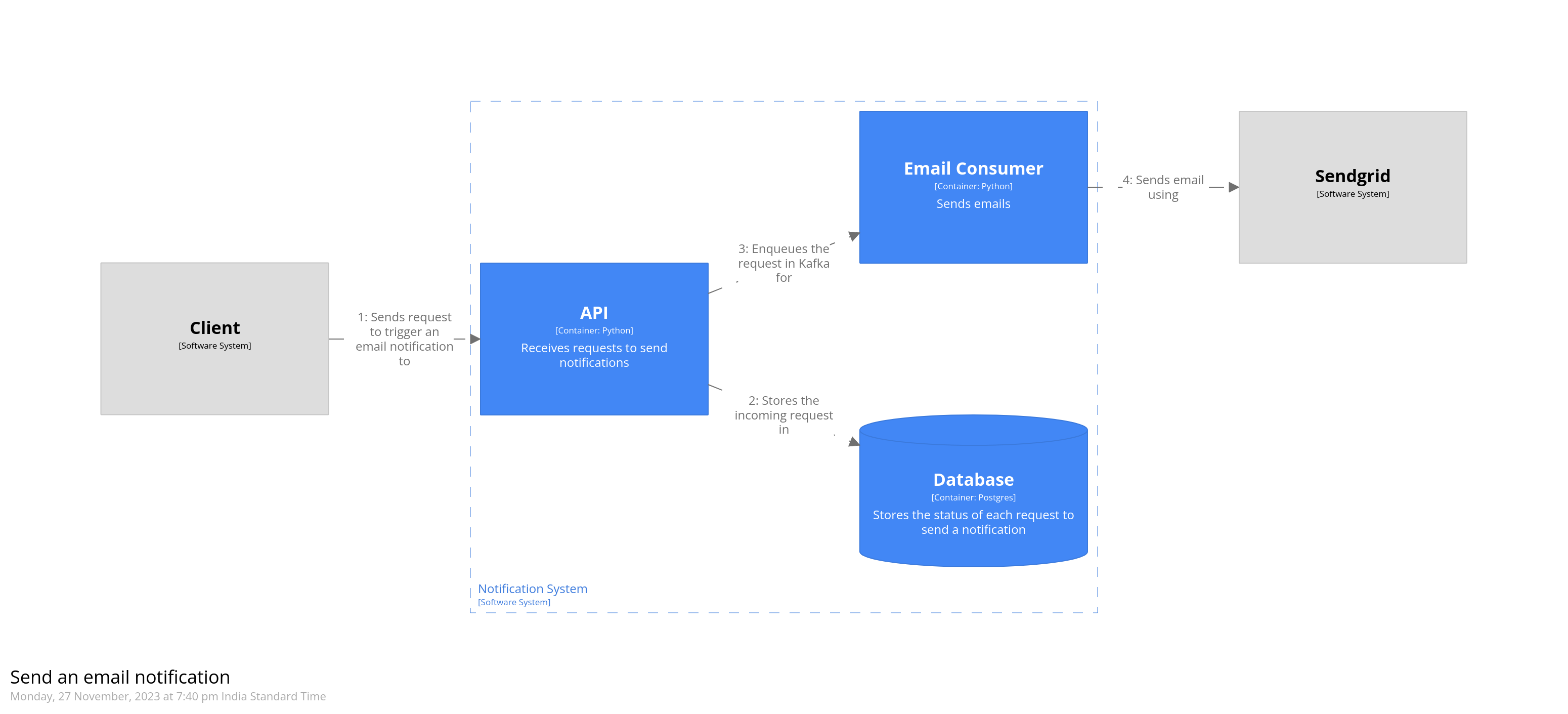
Now let’s look at our notification delivery system. It consists of a REST API which allows callers to send notifications across various channels like email, SMS, or push notifications. Every incoming request is added to a Kafka topic, depending on the channel of delivery, and is eventually picked up by background consumers. The status of each request is updated in the database. A CDC pipeline reads from this database and stores it into a warehouse. The diagram below gives an overview of what the system would look like.
Getting Started
My tool of choice for creating architecture diagrams as code is Structurizr. It provides a DSL which lets us create C4 model of our systems. When you visit its homepage, you’d find an example of how the same code can generate different views of the system at different levels of abstraction. We will use the open-source version of the tool, called Structurizr Lite, which allows a single person to create, edit, and view diagrams; in other words, there is no collaborative editing. The workflow we are aiming for lets individuals submit architecture diagrams as a part of their pull requests. In the next section, we will create a script which will let us run Structurizr Lite as a Docker container. We will then create the diagram that we saw above using the Structurizr DSL.
start.sh
We’ll start by organizing our Git repository. At the top level is the design folder where we will keep all the Structurizr code. The start.sh script, also at the top level, will launch the Docker container and reference the files in the design folder.
1 2 3 4
. ├── app.py ├── design └── start.sh
The content of the start script is the following:
1 2 3 4 5 6 7 8 9 10
#! /bin/bash
if [ -z $1 ]; then echo"You should provide a file name" exit 1 fi
We pass the name of the file as the first argument when we run the script. It is stored in the /usr/local/structurizr directory of the container which we have mapped to the design folder of our Git repository. When we run the script and the file does not exist, Structurizr creates it for us. This is helpful when we are creating a new diagram. If the file exists, Structurizr will read from it and render the diagrams. Let’s start by creating our first file.
1
./start.sh 001-overview
This will create two files under the design folder. The one we’d like to edit ends with dsl extension and will be committed to the repositiory. It is okay to add the json file to gitignore as that will be generated again when the container runs.
views { systemLandscape notificationSystem "Overview" { include * autoLayout lr }
systemContext notificationSystem "Context" { include * autoLayout lr } } }
Let’s unpack what is going on here. At the top-level is the workspace which is a container for the model and views. A model contains the different pieces of our architecture. This includes the software system we are describing, the people and external systems it interacts with, and the relationships between them. views contains the different levels of abstractions at which we’d like to see the system. Here we’ve defined the system landscape view, and the system context view.
In the model we’ve defined various software systems and the relationships between them. The system that we’d like to diagram is the notificationSystem. At this stage we’ve just added a one-line definition of the system, as softwareSystem, which results in it being rendered as a box in the diagram with its name on it.
We’ll continue to refine this diagram by defining other parts which together comprise the notification system. We will do so by adding them as children of the notification system which we’ve defined in the DSL. In other words, we will add one more level of detail to the system.
Relationships between the different parts of the system are defined using an arrow ->. These can be added as children of a softwareSystem or defined outside of them, as we’ve done above.
Adding more detail
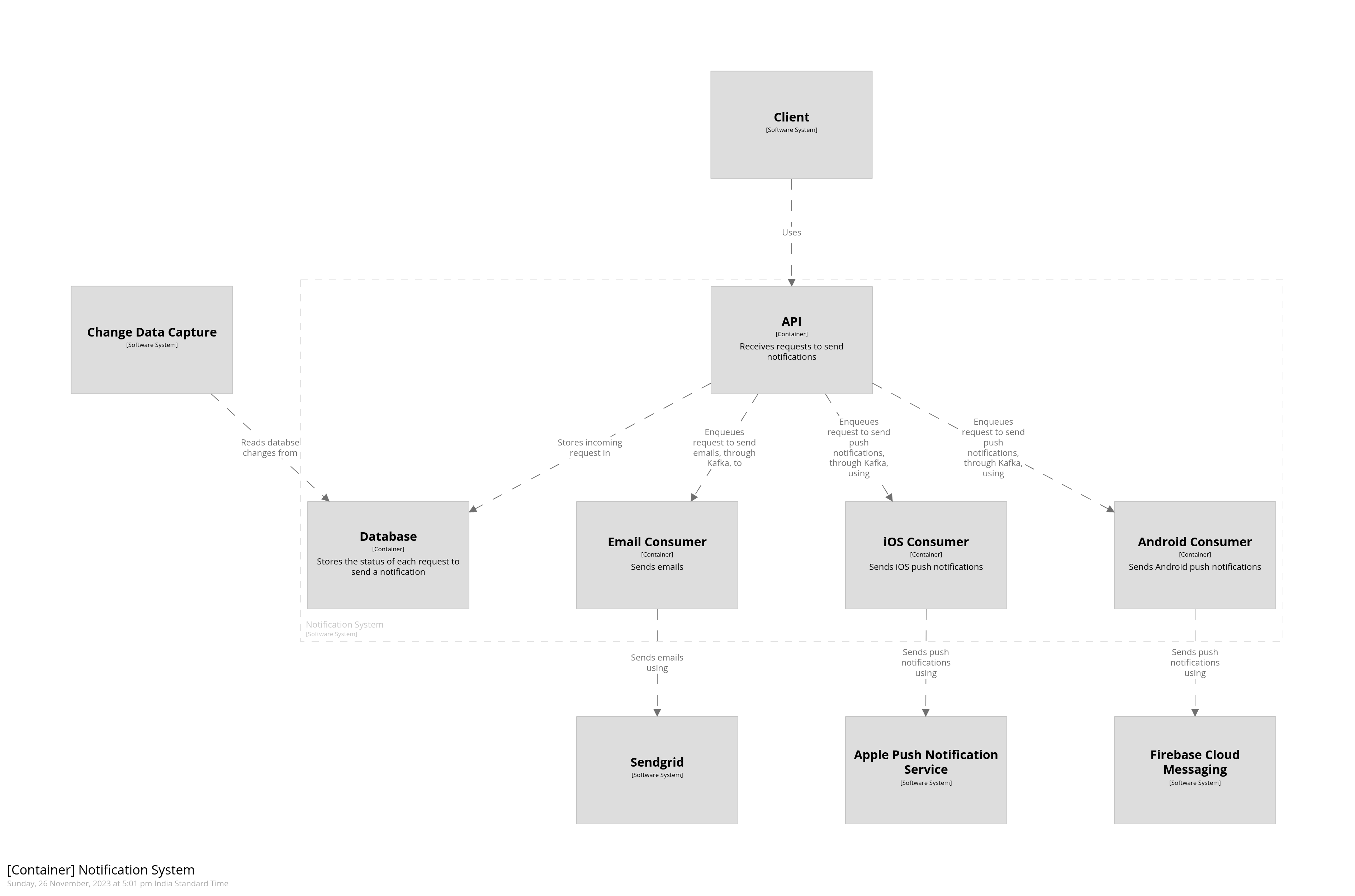
We will now zoom in and add the containers which make up the notification system. We will add the background consumers which consume the notifications enqueued in Kafka and send them to the relevant channel. Update the contents of the dsl file to the following:
# -- Relationships between systems user -> api "Uses" api -> email "Enqueues request to send emails, through Kafka, to" email -> sendgrid "Sends emails using"
api -> ios "Enqueues request to send push notifications, through Kafka, using" ios -> apns "Sends push notifications using"
api -> android "Enqueues request to send push notifications, through Kafka, using" android -> fcm "Sends push notifications using"
# -- Relationships between components api -> db "Stores incoming request in" }
views { systemLandscape notificationSystem "Overview" { include * autoLayout lr }
systemContext notificationSystem "Context" { include * autoLayout lr }
container notificationSystem "Container" { include * autoLayout tb } }
}
Notice that we’ve added components which are children of the notification system. We’ve also changed the relationships to point to these components instead of the parent software system. This keeps the system landscape and the system context diagrams the same but allows us to add a new container diagram to the system. This diagram is shown below.
You can add more detail by creating a component diagram. This will let you show individual parts of your software that perform specific tasks. For example, a REST API controller which handles incoming requests to send notifications. Although possible, it is recommended to add a component diagram only if it adds value. Usually it’d be sufficient to only create a container diagram.
Styling our diagram
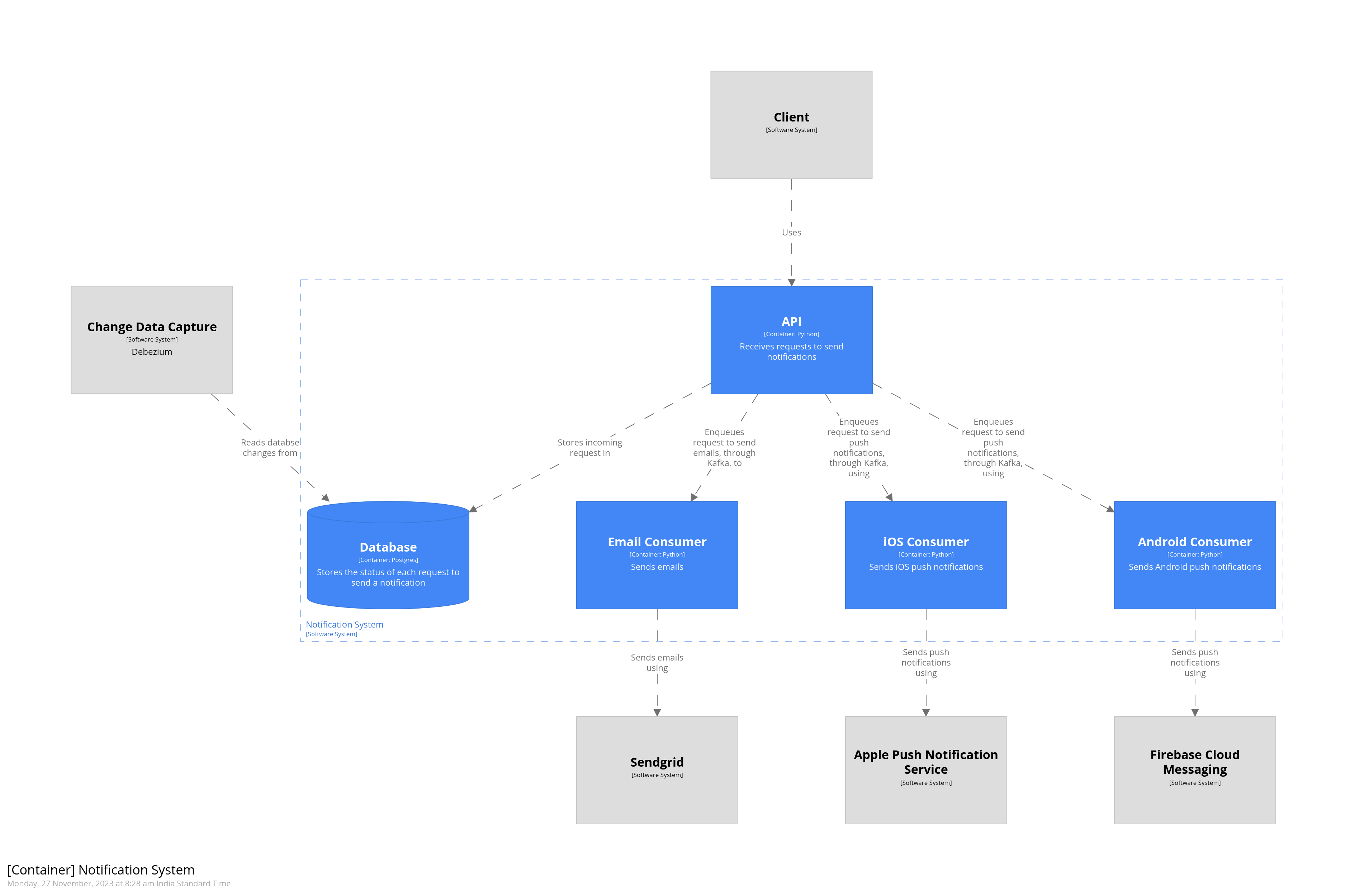
The diagram we’ve created so far conveys the architecture. However, the only indication of what is internal to the notification system, i.e. within the scope of the system, is a faint dashed line which groups various components together. Let’s go ahead and style our diagram by making components that are a part of the notification system render with a blue background. We’ll start by creating a few directories under design directory.
We’ve created three directories. styles will contain files which store styling information. icons is where we will keep PNG icons. themes is where we will store predefined themes. This is what the directory structure will look like.
Let’s create default.dsl under the styles directory. The contents of the file are given below.
1 2 3 4 5 6 7 8 9 10 11 12
styles { element "internal" { background #4287f5 color #ffffff }
element "database" { shape Cylinder }
}
Here we are creating a couple of custom elements. We are creating an internal element which has a blue background color, and a database element which is a cylinder. We will then use these elements to style our diagram. Let’s update the dsl file to include these elements. I’m only showing the parts that have changed for the sake of brevity.
We begin by including the styling information using the !include directive under views. Styling information is associated with individual systems and components by using tags. You can combine tags to apply multiple styles. Tags can be specified in-line or as a child of a software system or a component. We’ve specified the internal tag in-line for the api container, and as a child of the db container. Notice how we’ve applied both the internal and database tags to the db container, causing it to be rendered as a blue cylinder. With styling, the container diagram now visually communicates what is within and outside the scope of the notification system.
Dynamic diagrams
The diagrams we’ve created so far are static and only show the structure of the system. Dynamic diagrams allow us to show the flow of information between systems as a sequence of steps. They are like UML sequence diagrams but allow a more free-form arrangement of the various parts of the system. The steps are numbered to show the order in which they happen.
As an example, let’s model how an email notification would be triggered. The API receives a request to send an email. It stores this incoming request in the database, and then puts it into a Kafka topic. The consumer then picks up this request, and sends the email using a third-party system.
Dynamic diagrams are created using the dynamic element under views. To model the scenario mentioned above, we’d add the following to our dsl file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
views { ...
dynamic notificationSystem { title "Send an email notification" user -> api "Sends request to trigger an email notification to" api -> db "Stores the incoming request in" api -> email "Enqueues the request in Kafka for" email -> sendgrid "Sends email using" autoLayout lr }
... }
The steps are written in the order in which they appear. Numbers indicating their sequence are added automatically by Structurizr. The dynamic diagram for the code we just added is given below.
Deployment diagrams
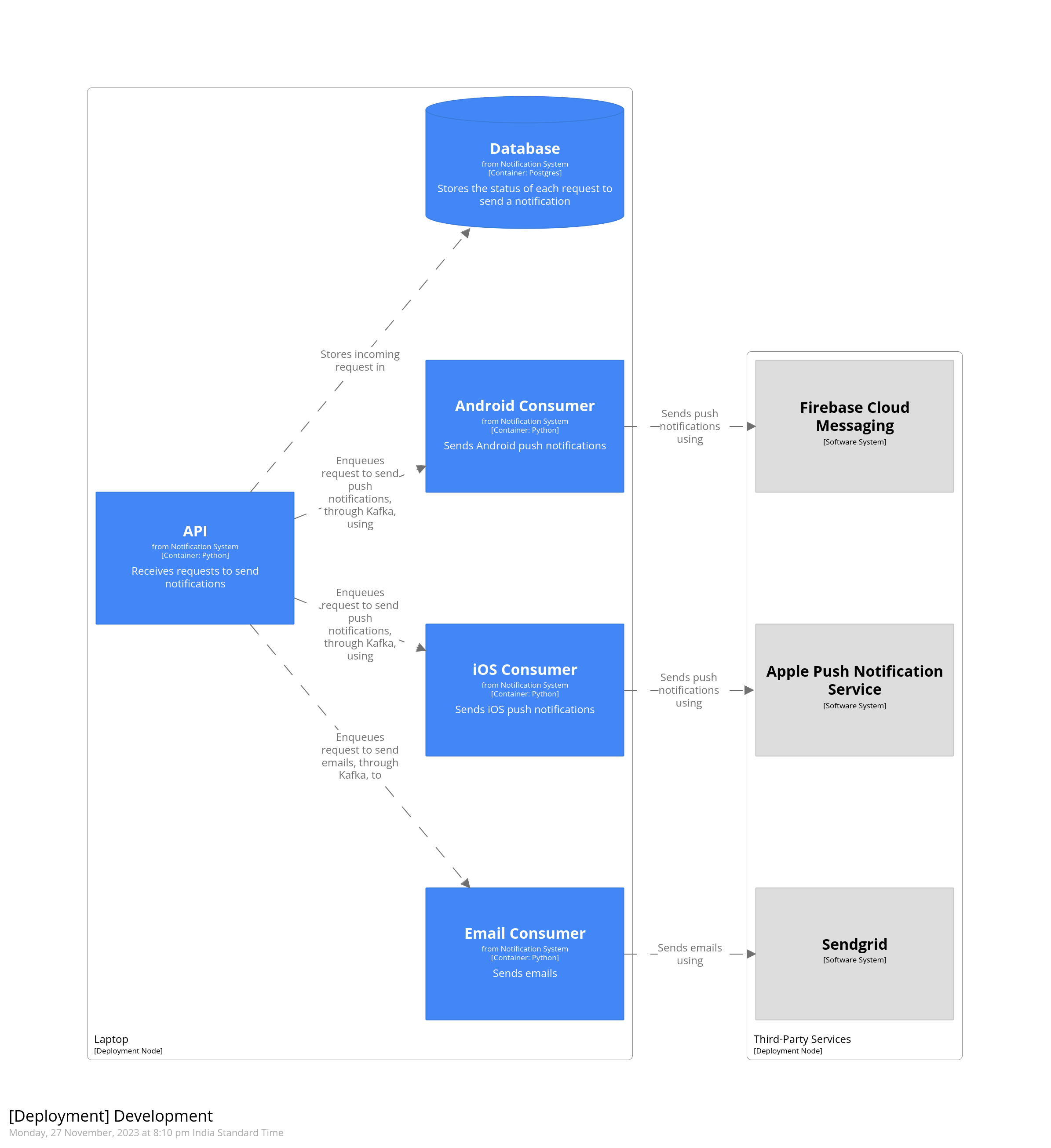
Deployment diagrams allow us to show how the software will actually run. For example, the various components of the software can be deployed as containers running on a Kubernetes cluster. We’ll start by creating a simple deployment diagram which shows the local development environment. All of the services, except the ones that are third-party, will run on the developer’s laptop.
Deployment diagrams are created by adding a model under model using the deploymentEnvironemnt keyword. Once that is defined, we include it in the views. Let’s model the development environment.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
model { ... development = deploymentEnvironment "Development" { deploymentNode "Laptop" { containerInstance api containerInstance email containerInstance ios containerInstance android containerInstance db }
We’re creating a node called “Laptop” which will host all the components running on the developer’s local machine. To this we add the various containers. We add another node to contain all the third-party services. Relationships between these are automatically inferred from the container diagram created previously. Finally, we add it to views
1 2 3 4 5 6 7 8
views { ... deployment * development { include * autoLayout lr } ... }
This gives us the following diagram.
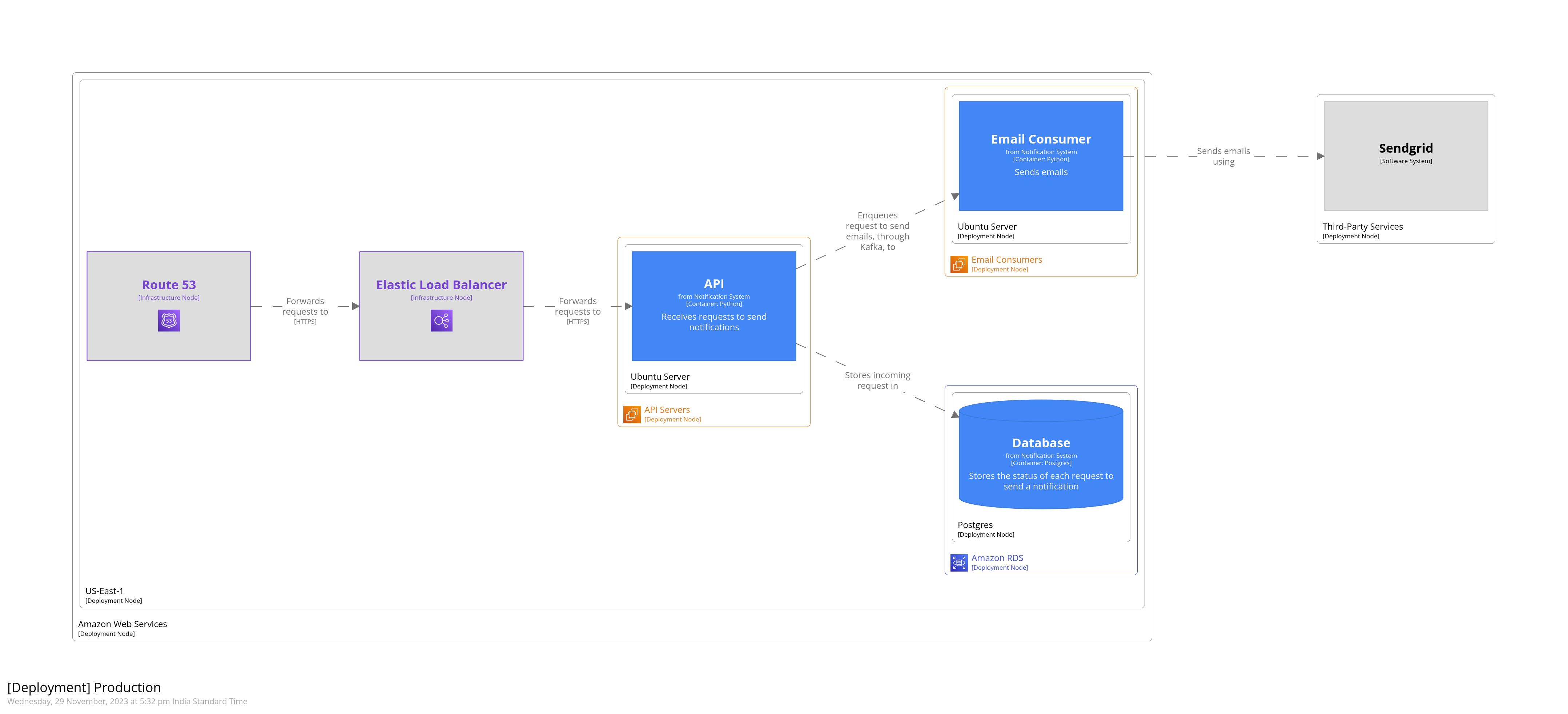
We can also depict how the software would be deployed to production. Let’s say that our system is deployed to AWS. Our databse is an RDS cluster, and API servers and email consumers are deployed to EC2 instances. We use Route52 for DNS, and Elastic Load Balancer to forward requests to the API servers. Like we did for the development environment above, we’ll create a deployment diagram. This diagram, however, will be styled some more to indicate the various AWS services.
Structurizr allows importing themes. Themes provide predefined tags which you can use to style elements of your diagram. Themes are added to views. Let’s start by adding the AWS theme.
Next we’ll model the production environment. In the model below, we’re nesting deployment nodes. The outermost node represents the AWS environment as a whole. The next node represent the AWS region. Being able to nest deployment nodes allows us to reuse elements of a diagram. For example, if we had multiple database clusters that were all hosted on Amazon RDS, we could nest them all under a single deployment node representing Amazon RDS.
We’ve added Route52 and ELB as infrastructure nodes, and defined relationships between them. They’re styled using tags that we imported from the AWS theme. These are defined in the JSON that’s returned from the theme’s URL.
You don’t need to add relationships between deployment nodes that host your containers. These relationships are implied from the container diagram that was created above.
Finally, we’ll add the production environment to views.
1 2 3 4 5 6 7 8
views { ... deployment * production { include * autoLayout lr } ... }
This gives us the following diagram. Notice how adding tags has caused AWS icons to be added and styling to be applied, wherever applicable. This is a very small subset of the overall system. Some of the background consumers, CDC, and warehouse have been omitted.
That’s it. That’s how you can create software architecture using code. I’ve created a Github repository for this blog post which contains the complete code for creating the notification system we discussed above.
Over the last few weeks I’ve been looking at ways to create a data warehouse. The aim is to bring together disparate sources of data so that they can be analysed to create reports and dashboards. There are many open-source and closed-source options available like Snowflake, Clickhouse, Apache Pinot, etc. However, I ended up settling for Apache Doris. In this post I will go over how you can replicate data into Doris using Kafka. I will use Debezium to replicate a Postgres table into the warehouse.
Setting things up
My setup consists of Docker containers for Kafka, Debezium, Postgres, and Doris. In a nutshell, I’ll create a table in Postgres, have Debezium stream it to Kafka, and then use the Kafka consumer in Doris to ingest this into a table. After the JSON generated by Debezium has been written to a table, I’ll create a view on top of this data to make it look relational again.
Before we begin
Doris ships with “external table” ingestion for Postgres. However, the caveat is that you’d have to import the data in small batches manually. Additionally, the external connector is configured for a single database table. If you have a setup where every tenant gets their own table then the data can be split among multiple databases (for MySQL) or schemas (for Postgres) on the same cluster. Setting up external tables becomes difficult. This is because new databases or schemas can be added dynamically and would require an external table to be setup for them. In contrast, you could have Debezium fetch tables based on a regex pattern. Any table in any database or schema that matches the pattern would be a valid candidate for Debezium to stream from.
Another reason for using Debezium is to avoid reingesting the data when new columns are added to the table. Since we will store the raw JSON payload that Debezium sends, we can simply update the view and extract the new column from the JSON.
The final reason for using Debezium is to be able to support databases that Doris doesn’t have external table support for. For example, MongoDB. Using Debezium allows us to stream these databases into Kafka and then into Doris.
Getting started
We’ll begin by bringing up the containers. For the purpose of this demo, we will create a table called people and add some rows to it. Here is what a row from this table looks like:
1 2 3
| customer_id | id | name | created_at | updated_at | deleted_at | |-------------|--------|--------------|----------------------------|------------|------------| | 1 | 108923 | Cynthia Ford | 2023-11-02 15:50:42.158417 | NULL | NULL |
After the table is populated, we’ll create a Debezium source connector to stream the table to Kafka. The configuration for this connector looks like this:
Notice how we’re specifying a regex pattern for table.include.list in the configuration. This would match people table in any schema within the postgres database. We are also using the route transformer to merge the tables from various schemas into a single Kafka topic.
Now that the data is in Kafka, we can begin ingesting it into Doris. We will do this as a two-step process. One, we will ingest this into a landing area where we store the raw JSON payload along with the primary key. Two, we will create a view on top of this data and extract the keys that we need.
We’ll create a database called ingest where we will store the raw data.
1
CREATE DATABASE ingest;
Within this database, we will create a table called people where the data from Kafka will be stored.
1 2 3 4 5 6 7 8 9 10 11 12 13
CREATETABLE IF NOTEXISTS ingest.people ( id BIGINT, customer_id BIGINT, source JSONB, op VARCHAR, ts_ms BIGINT ) UNIQUE KEY (id, customer_id) DISTRIBUTED BY HASH (customer_id) BUCKETS 1 PROPERTIES ( "replication_num" = "1", "enable_unique_key_merge_on_write" = "true" );
The source column will store the JSON generated by Debezium. We will extract column values from this when we create the view. We are specifying the combination of customer_id and id as the UNIQUE KEY and enabling merge-on-write in properties. This allows us to keep the latest version of the row as we read updates from Debezium. Since all of this running on my local machine, I’ve set the replication to 1. Without this setting Doris would not allow creating tables as there aren’t at least 3 instances of Doris backend running.
To begin loading data from Kafka, we will create a ROUTINE LOAD. This will read data from Kafka in batches and write them to the people table.
In the definiton of the routine load we are specifying the table to write into using the ON clause. In the properties we specify that we are ingesting JSON objects from Kafka. We also specify jsonpaths which allows us to select keys from within the JSON payload. We are extracting keys that would become columns in the raw people table. Since jsonpaths is a stringified JSON list, we need to escape the quotes. Finally, we specify the Kafka broker and the topic to read from.
You can see the running task using
1
SHOWALL ROUTINE LOAD FOR ingest.load_people;
After waiting for some time to let the task finish ingesting the rows we can create the view. We’ll start by creating the database.
1
CREATE DATABASE warehouse;
Finally, we will create the view
1 2 3 4 5 6 7 8 9
CREATEVIEW warehouse.people AS SELECT id, customer_id, REPLACE(json_extract(source, '$.name'), "\"", '') AS name, FROM_UNIXTIME(CAST(replace(json_extract(source, '$.created_at'), "\"", '') ASBIGINT) /1000) created_at, FROM_UNIXTIME(CAST(replace(json_extract(source, '$.updated_at'), "\"", '') AS BIGINT) / 1000) updated_at, FROM_UNIXTIME(CAST(replace(json_extract(source, '$.deleted_at'), "\"", '') ASBIGINT) /1000) deleted_at FROM ingest.people;
In the SQL above, we are extacting the fields from the JSON that we stored. We are processing them to remove quotations, and converting the epoch sent by Debezium to a DATETIME object. Since we have enabled merge-on-write, subsequent updates to the source table in Postgres would be reflected automatically in the view.
We can now see the data stored in the view.
1
SELECT*FROM warehouse.people LIMIT 1;
and this gives us
1 2 3
| customer_id | id | name | created_at | updated_at | deleted_at | |-------------|-------|----------------|---------------------|------------|------------| | 1 | 28910 | Douglas Becker | 2023-11-03 11:42:09 | NULL | NULL |
That’s it. That’s how you can set up a real-time data warehouse using Doris, Debezium, and Kafka.
Lately I have been spending some time on Reddit’s /r/SQL and a question that comes up frequently is where to find good resources to learn SQL. This post traces a learning path. I will list down courses, books, and websites which you can use to learn SQL.
Getting Started
The first step is to get comfortable with the relational model. Depending on whether you prefer books or courses, you can pick one of the following.
The course, offered by Stanford on edX, provides an introduction to relational databases and SQL. It assumes no prior knowledge of either relational databases or SQL. It is the first in a series of 5 courses with each course covering a more advanced aspect of SQL and relational model. As of writing, the course costs USD 50 for the certificate track.
If you are a reader, Learning SQL by Alan Beaulieu is the book for you. It begins with a quick introduction of the relational model and then dives head-first into writing SQL queries. It explains everything by examples and also provides exercises at the end of each chapter to solidify learning. The book is intended to be read cover to cover as each chapter builds upon the previous one. You will find a comprehensive coverage of SQL from the basics of creating tables, to inserting, retrieving, and deleting data, to the more advanced analytical functions.
If you’re looking for a free alternative to learn SQL then you can use SQLBolt. It begins with a quick one-page introduction of relational databases and then takes you straight into writing SQL queries. The good part about SQLBolt is that you do not need to set up any database on your local machine. You can do all the exercises right in the browser.
SQLBolt is a good website to learn the basics of SQL. However, there are a few topics which are yet to be covered. These are topics of intermediate difficulty and you will have to find alternative resources to learn them.
Practice, Practice, Practice
Once you have a firm grasp of the basics, the next step is to get some practice.
PgExercises is a good place to start practicing your new SQL skills. You are presented with the database of a fictitious country club on which the problems are based. The problems begin with simple retrieval of data and gradually become more involved by introducing conditional statements, and so on. The nice thing about PgExercises is that you can solve all the problems on the website itself and get immediate feedback on whether your answer is correct or not. There is an option to get a hint if you are stuck and to view the answer if you are really stuck.
You can also use PgExercises to prepare for an interview. Set a timer when solving the exercises and don’t look at the hints. This will give you an indication of how prepared you are.
If you’re asked to find out the maximum or minimum value among a group of rows, you’d probably come up with a combination of GROUP BY clause along with MIN or MAX functions. What if, instead, you were asked to rank your results in decreasing order? SQL allows you to do that using the RANK function.
MIN, MAX, and AVG are aggregate functions whereas RANK is a window function. If you’d like to learn how to use window functions, click on the link in the title. The Window Functions website begins with a refresher on GROUP BY and HAVING clauses and then proceeds to introduce you to window functions. Like PgExercieses, you’ll be solving problems in an interactive editor using Postgres. All this on a cute dataset of cats.
Use Window Functions and PgExercises to prepare for your upcoming interviews.
If you are looking for something more mind-bending then head over to AdvancedSQLPuzzles. It is a collection of 40 puzzles that will help you determine your level of expertise with SQL. The only caveat to using the website is that you will have to put in some effort to set up a local database before you can start solving the puzzles. Additionally, the solutions are written in T-SQL so you might need to translate the solutions to your favorite dialect of SQL.
When it comes to statistics, there’s two schools of thought - frequentism and Bayesianism. In the coming posts we’ll be looking at hypothesis testing and interval estimation and knowing the difference between the two schools is important. In this post I’ll go over what frequentism and Bayesianism are and how they differ.
What is ‘probability’?
The reason for these two schools of thoughts is the difference in their interpretation of probability. For frequentists, probabilities are about frequency of occurence of events. For Bayesians, probabilities are about degree of certainty of events. This fundamental divide in the definition of probability leads to vastly different methods of statistical analysis.
The two schools
The aim of both the frequentists and Bayesians is the same - to estimate some parameters of a population that are unknown.
The assumption of the frequentist approach is that the parameters of a population are fixed but unknown constants. Since these are constants, no statements of probability can be made about them. The frequentist procedures work by drawing a large number of random samples, calculating a statistic using each of these samples, and then finding the probability distribution of the statistic. This is called the sampling distribution. Statements of probability can be made about the statistic.
The assumption of the Bayesian approach is that the parameters of a population are random variables. This allows making probability statements about them. There is a notion of some true value that the parameters can take with certain probability. The Bayesian approach thus allows adding in some prior information. The cornerstone of Bayesian approach is Bayes’ theorem:
Here, is the hypothesis and is the data. What the theorem lets us calculate is the posterior which is the probability of the hypothesis being true given the data. The prior is the probability that is true before the data is considered. The prior lets us encode our beliefs about the parameters of the population into the equation. is the likelihood and is the evidence about hypothesis given data . Finally, is the probability of getting the data regardless of the hypothesis.
What’s important here is the prior . This is our degree of certainty about the hypothesis being true. This probability can itself be calculated using frequentist methods but what matters is the fact that Bayesian approach lets us factor it in.
Frequentist
Bayesian
Parameters are fixed, unknown constants. No statements of probability can be made about them.
Parameters are random variables. Since random variables have an underlying probability distribution, statements of probability can be made about them.
Probability is about long run frequencies.
Probability is about specifying the degree of (un)certainty.
No statements of probability are made about the data or the hypothesis.
Statements of probability are made about both data and hypothesis.
Makes use only of the likelihood.
Makes use of both the prior and the likelihood.
The procedures
In the frequentist approach, the parameters are an unknown constant and it is the data that changes (by repeated sampling). In the Bayesian approach, the parameters are a random variable and it is the data that stays constant (the data that has been observed). In this section we will contrast the frequentist confidence interval with Bayesian credible interval.
Both confidence intervals and credible intervals are interval estimators. Interval estimators provide a range of values that the true parameters can take.
The frequentist confidence interval
Let’s assume that there’s a true parameter , representing the mean of a population, that we are trying to estimate. From a sample of values we can then construct two estimators and and say that the true value lies between and with a certain level of confidence.
To be confident that , we need to know the sampling distribution of the estimator. If the random variable is normally distributed, then the sample mean is also normally distributed with mean (true mean) and variance i.e. . In a normal distribution, 95% of the area under the curve is covered by two standard deviations. Therefore, if we want 95% of the intervals to contain the true value of , we can construct an interval .
What this means is that if we were to keep drawing samples and constructing these intervals, 95% of these random intervals will contain the true value of the parameter . This can be stated more generally as . This means that with probability (with ), the interval between and contains the true value of the parameter . So, if we set , we’re constructing a 95% confidence interval. is called the level of significance and is the probability of committing type I error.
Let’s suppose we’re trying to find the average height of men. It is normally distributed with mean and standard deviation inches. We take a sample of and find that the sample mean inches. The 95% confidence interval would be . This gives us the confidence interval . This is one such interval. If we were to construct 100 such intervals, 95 of them would contain the true parameter .
The caveat here is that for simplicity I’ve assumed the critical value to be 2 instead of 1.96 for constructing the interval.
The Bayesian credible interval
A Bayesian credible interval is an interval that has a high posterior probability, , of containing the true value of the parameter. Compared to the frequentist confidence intervals which say that of all the intervals calculated will contain the true parameter , the Bayesian credible interval says that the calculated interval has probability of containing the true parameter.
Let’s suppose we’re interested in the proportion of population [1] that gets 8 hours of sleep every night. The parameter here now represents proportion. A sample of 27 is drawn of which 11 get 8 hours of sleep every night. Therefore, the random variable .
To calculate a Bayesian credible interval, we need to assume a subjective prior. Suppose the prior was . The posterior would thus be . This can be calculated using scipy as follows:
1 2 3
from scipy import stats stats.beta.interval(0.9, 14.3, 23.2) (0.256110060437748, 0.5138511051170076)
The 90% credible interval is (0.256, 0.514).
In summary, here are some of the frequentist approaches and their Bayesian counterparts.
Frequentist
Bayesian
Max likelihood estimation (MLE)
Max a posteriori (MAP)
Confidence interval
Credible interval
Significance test
Bayes factor
A thing that I have glossed over is handling of nuisance parameters. Bayesian procedures provide a general way of dealing with nuisance parameters. These are the parameters we do not want to make inference about, and we do not want them to interfere with the inference we are making about the main parameter. For example, if we’re trying to infer the mean of a normal distribution, the variance is a nuisance parameter.
The critique
The prior is subjective and can change from person to person. This is the frequentist critique of the Bayesian approach; it introduces subjectivity into the equation. The frequentist approach make use of only the likelihood. On the other hand, the Bayesian criticism of the frequentist approach is that it uses an implicit prior. Bayes theorem can be restated as . For the frequentist approach, which makes use of likelihood, the prior would need to be set to 1 i.e. a flat prior. The Bayesian approach makes the use of prior explicit even if it is subjective.
The Bayesian criticism of frequentist procedures is that they do not answer the question that was asked but rather skirt around it. Suppose the question posed was “in what range will the true values of the parameter lie?”. The Bayesian credible interval will give one, albeit subjective, interval. The frequentist confidence interval, however, will give many different intervals. In that sense, frequentism isn’t answering the question posed.
Another Bayesian criticism of the frequentist procedures that they rely on the possible samples that could occur but did not instead of relying on the one sample that did occur. Bayesian procedures treat this sample as the fixed data and vary the parameters around it.